

The SQL Server 2022 is coming with fantastic new features. One of these features is Parameter Sensitive Plan Optimization.
The stored procedures are very useful and have a lot of advantages for the performance and the security.
You can see the differences between the ad hoc queries and the stored procedures below.
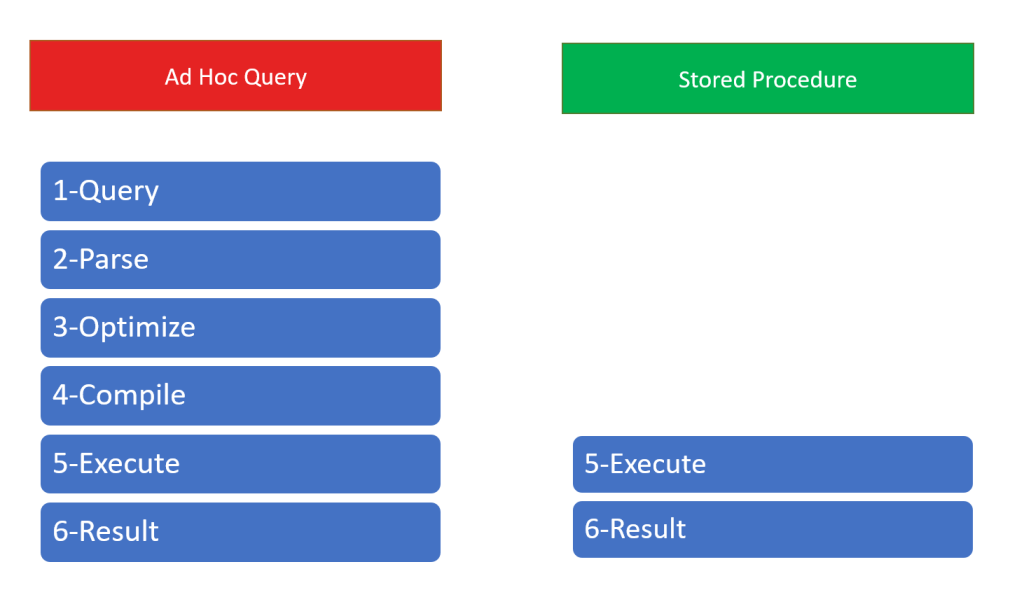
A query process completes with 6 steps in an ad hoc query. But it completes with 2 steps in stored procedures.
The first 4 steps run when the procedure first executed and then the execution plan stored in cache. The next time, we execute the stored procedure, we don’t need to run first 4 steps. Because it is still on cache. This situation is very useful and it increases the query performance.
But sometimes, it can cause a performance down. It depends on the first execution parameter.
The execution plan is created for the first parameter. And the execution plan contains the index for calling the stored procedure. If the next time, we call the stored procedure with a different parameter, need a different index, the cached plan chooses the wrong index and the query will be slower.
If we use the ad hoc query according to stored procedure, our query execution plan will choose the correct index. Because, when we call an ad hoc query, the execution plan is calculated for every query.
This is the problem.
The stored procedures, can be call with different parameters and every parameter may need different indexes, but the stored procedure has just one execution plan and one index.
And this is the solution!
The SQL Server 2022 has a new feature for this problem. We can store more than one execution plan for a stored procedure.
I will explain it with a dataset.
You can use the script below to create the sample database.
CREATE DATABASE SALESPSP
GO
USE SALESPSP
GO
CREATE TABLE ITEMS (ID INT IDENTITY(1,1) PRIMARY KEY,ITEMNAME VARCHAR(100),PRICE FLOAT)
DECLARE @I AS INT=1
DECLARE @PRICE AS FLOAT
DECLARE @ITEMNAME AS VARCHAR(100)
WHILE @I<=100
BEGIN
SET @PRICE =RAND()*10000
SET @PRICE=ROUND(@PRICE,2)
SET @ITEMNAME='ITEM'+REPLICATE('0',3-LEN(@I))+CONVERT(VARCHAR,@I)
INSERT INTO ITEMS (ITEMNAME,PRICE) VALUES (@ITEMNAME,@PRICE )
SET @I=@I+1
END
SELECT * FROM ITEMS
CREATE TABLE CUSTOMERS (ID INT IDENTITY(1,1) PRIMARY KEY,CUSTOMERNAME VARCHAR(100))
SET @I=1
DECLARE @CUSTOMERNAME AS VARCHAR(100)
WHILE @I<=100
BEGIN
SET @CUSTOMERNAME='CUSTOMER'+REPLICATE('0',3-LEN(@I))+CONVERT(VARCHAR,@I)
INSERT INTO CUSTOMERS (CUSTOMERNAME) VALUES (@CUSTOMERNAME)
SET @I=@I+1
END
CREATE TABLE SALES (ID INT IDENTITY(1,1) PRIMARY KEY,ITEMID INT,CUSTOMERID INT,DATE_ DATETIME,AMOUNT INT,PRICE FLOAT,TOTALPRICE FLOAT,DEFINITION_ BINARY(4000))
SET @I=0
DECLARE @ITEMID AS INT
DECLARE @AMOUNT AS INT
DECLARE @CUSTOMERID AS INT
DECLARE @DATE AS DATETIME
WHILE @I<500000
BEGIN
DECLARE @RAND AS FLOAT
SET @RAND =RAND()
IF @RAND<0.9
SET @ITEMID =1
ELSE
SET @ITEMID=(RAND()*99)+1
SELECT @PRICE=PRICE FROM ITEMS WHERE ID=@ITEMID
SET @CUSTOMERID=(RAND()*99)+1
DECLARE @DAYCOUNT AS INT
DECLARE @SECONDCOUNT AS INT
SET @AMOUNT=(RAND()*19)+1
SET @DAYCOUNT=RAND()*180
SET @SECONDCOUNT=RAND()*24*60
SET @DATE=DATEADD(DAY,@DAYCOUNT,GETDATE())
SET @DATE=DATEADD(DAY,@SECONDCOUNT,@DATE )
INSERT INTO SALES (ITEMID,CUSTOMERID,AMOUNT,PRICE,TOTALPRICE,DATE_)
VALUES (@ITEMID,@CUSTOMERID,@AMOUNT,@PRICE,@PRICE*@AMOUNT,@DATE)
SET @I=@I+1
END
CREATE INDEX IX1 ON SALES (ITEMID)
We have 100 rows in the ITEMS table.

And we have 100 rows for the CUSTOMERS table.


We have 500.00 rows for the SALES table.

In this script, we are creating the rows by choosing a random ITEMID and random CUSTOMERID. But there is more probability to choose the 1 value for the ITEMID.
As we can see below, we have about 450.000 rows for the ITEMID=1 and 500-600 rows for the other ITEMIDs.

We have a primary key and clustered index contains the ID field and we have a nonclustered index in SALES table.
Let’s run the query.
SET STATISTICS IO ON
SELECT ITEMID,SUM(AMOUNT) TOTALAMOUNT,
COUNT(*) ROWCOUNT_
FROM SALES
WHERE ITEMID=20
GROUP BY ITEMID

Now, Let’s look at the query statistics and learn how many page did the query read.
The query reads 1709 pages and it’s equal that 1709×8/1024=13 MB.

Now let’s look at the execution plan.

The server optimizes itself by choosing the IX1 nonclustered index.

If we look at the IX1 index, wee see the ITEMID column. It is normal. I send a parameter to the query as ITEMID and query choose the index contains ITEMID.

Well, what happens if the system does not find the correct index, but performs a clustered index scan over the primary key? Let’s see this by doing index forcing.
SET STATISTICS IO ON
SELECT ITEMID,SUM(AMOUNT) TOTALAMOUNT,
COUNT(*) ROWCOUNT_
FROM SALES WITH (INDEX=PK_SALES)
WHERE ITEMID=20
GROUP BY ITEMID
As you see, the read page count increased to two times. I think it’s not a big problem.
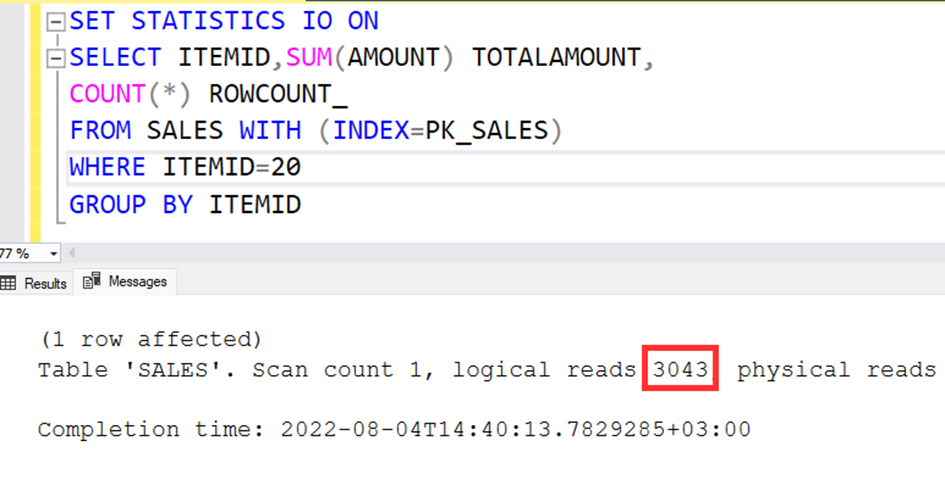
Well, Let’s call the query again with ITEMID=1.
SET STATISTICS IO ON
SELECT ITEMID,SUM(AMOUNT) TOTALAMOUNT,
COUNT(*) ROWCOUNT_
FROM SALES
WHERE ITEMID=1
GROUP BY ITEMID

The read page count is the same and 3043.

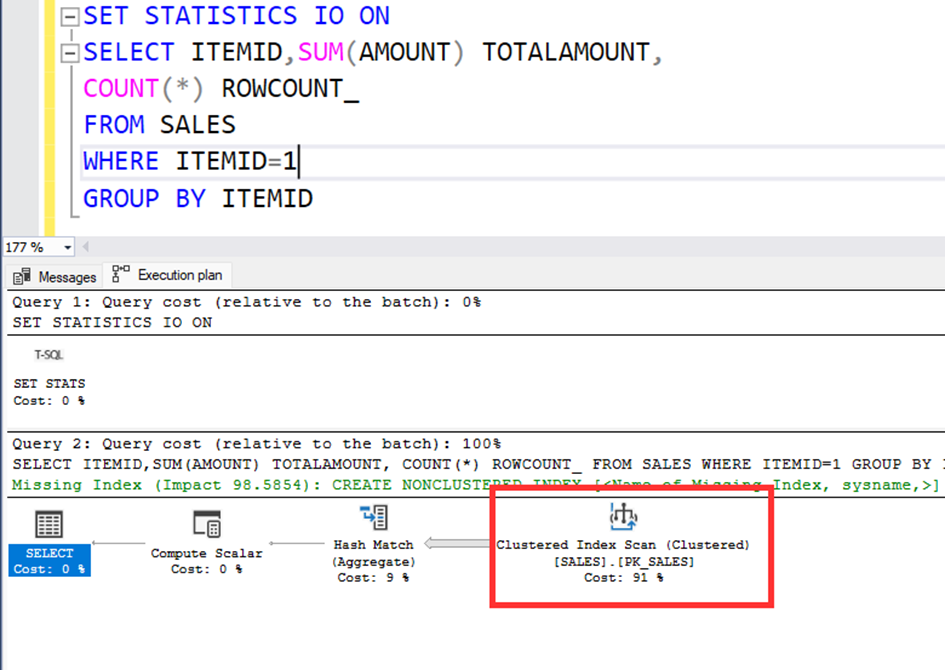
Let’s look at the execuion plan again.
According to execution plan, the system prefer the clustered index instead of nonclustered index. We know that, our parameter is ITEMID and we have an nonclustered index contains the ITEMID but the system choose the clustered index.
Because if we use the ITEMID=1, using the clustered index is more effective. Because there are 450.000 rows with the ITEMID=1.
Ok. Let’s force to use nonclustered index.
SET STATISTICS IO ON
SELECT ITEMID,SUM(AMOUNT) TOTALAMOUNT,
COUNT(*) ROWCOUNT_
FROM SALES WITH (INDEX=IX1)
WHERE ITEMID=1
GROUP BY ITEMID
As we can see, the system reads so much.

According to this rule, we have a risk. If the stored procedure will execute first with the parameter ITEMID=1, the procedure always use the clustered index for all the parameters. Or the first execution parameter’s frequency is less then, for example ITEMID=20, the execution plan will be create for the non clustered index.
In SQL Server 2022, we have a fantastic feature. The feature name is PSP (Parameter Sensitive Plan) Optimization. This feature allows to store mutiple execution plan for a stored procedure.
So we can use the stored procedures like the ad hoc queries.
Let’s try it. I create a stored procedure, named GETSALES_BY_ITEMID.
CREATE PROC [dbo].[GETSALES_BY_ITEMID]
@ITEMID AS INT
AS
BEGIN
SELECT ITEMID,SUM(AMOUNT) TOTALAMOUNT,
COUNT(*) ROWCOUNT_
FROM SALES
WHERE ITEMID=@ITEMID
GROUP BY ITEMID
END

Right click on the SALESPSP database, click properties and change the compatibility level to SQL Server 2019.


Now, run the procedure with ITEM=20 parameter.


Let’s look at the active execution plan.


Let’s look at the active execution plan.
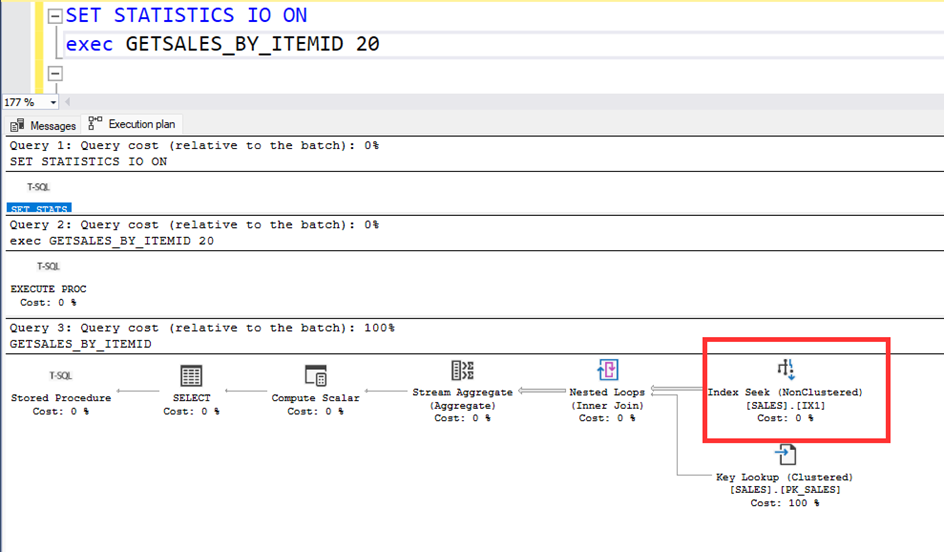
Let’s call the procedure with the parameter ITEMID=1, again the system uses the IX1 nonclustred index. But it is not correct index. The clustered index is better fort he ITEM=1.



When we call the procedure with ITEMID=1, the system uses the clustered index.

When we call the procedure with ITEMID=20, the system uses the non-clustered index.

Conclusion
The stored procedures are absolutely so important for the performance. But the stored procedures have only one execution plan for the different type of parameters. Because of this situation, the proc can choose the wrong index and it is not good for the performance.
In the SQL Server 2022, the stored procedures can store multiple execution plan and they can use the correct index, according to parameters. This is a really great feature. Thanks to SQL Server engineers.
I hope, you liked this article. See you on another article.
