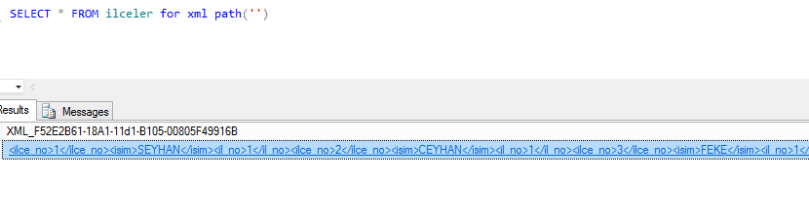
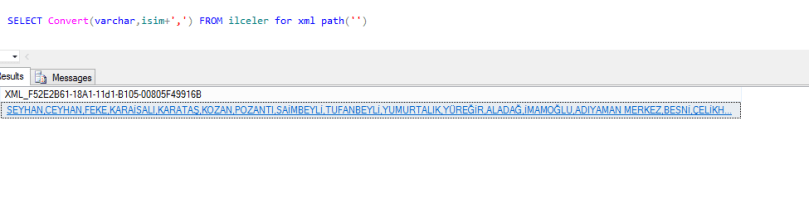
SQL Server ile Web Servise bağlanıp Json formatında hava durumunu çekme
Son dönemde bildiğiniz üzere farklı platformlar arasında en çok kullanılan ortak dil JSON oldu. Öyle ki 2000’li yılların başında bu noktada bir devrim gibi çıkan web servislerinin formatı olan XML’in yerini sahip olduğu avantajlar ile almış durumda.
JSON bu kadar popüler iken data ile uğraşan insanlar olarak bizim de MSSQL tarafında bu konuya kayıtsız kalmamız doğru olmaz diye düşünüyorum ve JSON formatını SQL tablosuna dönüştüren bir fonksiyonu sizinle burada paylaşıyorum. Her ne kadar 2017 versiyonunda MSSQL Json’a destek verse de önceki versiyonlarda kullanacağınız bir fonksiyonu paylaşıyorum.
Bu kodu bizimle paylaşan Scott Puleo’ya teşekkür ederiz.
Aşağıdaki linkte bulabilirsiniz.
Şimdi gelelim örneğimize internette hava durumunu api olarak json formatında bize veren bir site var.
https://samples.openweathermap.org/data/2.5/weather?q=London,uk&appid=b6907d289e10d714a6e88b30761fae22
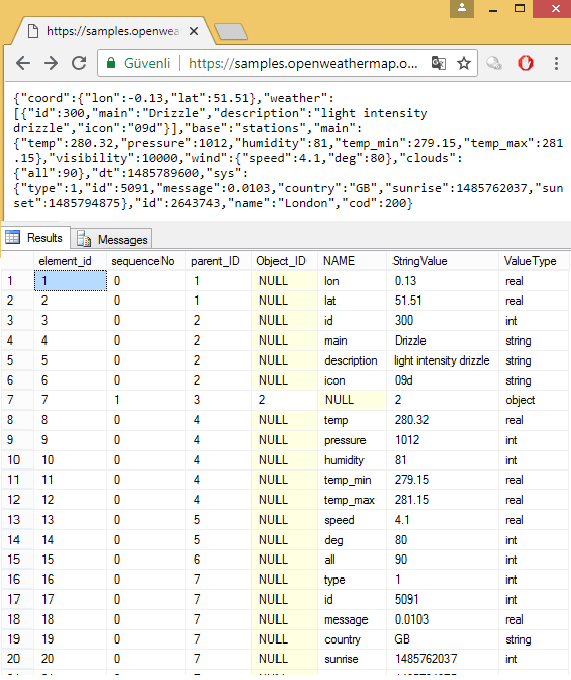
Örneğin burası bize Londra ile alakalı JSON bilgi döndürüyor.
Buradaki Json bilgisini bizim fonksiyonumuzda çağırdığımızda ise aşağıdaki gibi sonuç görürüz.
Şimdi bu işlemi web sayfasından doğrudan çekecek şekilde kodumuzu yazalım.
Bunun için Ole Automation procedure leri kullanacağız. Bu procedure leri kullanmak için
exec sp_configure ‘show advanced options’,1
reconfigure with override
exec sp_configure ‘Ole Automation Procedures’,1
reconfigure with override
Diyerek aktif hale getiriyoruz.
Sonra kodumuzu çalıştırdığımızda sonuç aşağıdaki gibi geliyor. Burada bu site bir örnek ve normalde paralı olarak bu hizmeti veriyor. Başka uygulamalara da bakılabilir. Ben ilk karşıma çıkan sayfayı denedim açıkçası.
Kodları aşağıda paylaşıyorum.
Önce JSON dbo.parseJSON fonksiyonunu oluşturmanız gerekiyor. Onun scripti uzun olduğu için en aşağıda. Sonra hemen alttaki sorguyu çalıştırmanız yeterli.
Görüşmek üzere.
Declare @RESULT as varchar(MAX)
Declare @JSON as varchar(MAX)
Declare @Object as int;
Declare @ResponseText as varchar(8000);
Declare @HResult int
Declare @Source varchar(255), @Desc varchar(255)
Declare @Body as varchar(8000) =”
—————————Web Servise Bağlanıp hava durumunu çeken kod———————
Declare @URL as varchar(MAX)=’https://samples.openweathermap.org/data/2.5/weather?q=London,uk&appid=b6907d289e10d714a6e88b30761fae22′
Exec SP_OACreate ‘MSXML2.XMLHTTP’, @Object OUT;
Exec SP_OAMethod @Object, ‘Open’, NULL, ‘GET’,
@URL, ‘false’
Exec SP_OAMethod @Object, ‘setRequestHeader’, NULL, ‘Content-Type’, ‘application-json’
Declare @Len int
Set @Len = len(@Body)
Exec SP_OAMethod @Object, ‘send’, NULL
Exec SP_OAMethod @Object, ‘ResponseText’, @ResponseText OUTPUT
Set @JSON = @ResponseText
select * from dbo.parseJSON(@JSON)
——————————–json formatını parse eden fonksiyon————————
CREATE FUNCTION dbo.parseJSON( @JSON NVARCHAR(MAX))
RETURNS @hierarchy TABLE
(
element_id INT IDENTITY(1, 1) NOT NULL, /* internal surrogate primary key gives the order of parsing and the list order */
sequenceNo [int] NULL, /* the place in the sequence for the element */
parent_ID INT,/* if the element has a parent then it is in this column. The document is the ultimate parent, so you can get the structure from recursing from the document */
Object_ID INT,/* each list or object has an object id. This ties all elements to a parent. Lists are treated as objects here */
NAME NVARCHAR(2000),/* the name of the object */
StringValue NVARCHAR(MAX) NOT NULL,/*the string representation of the value of the element. */
ValueType VARCHAR(10) NOT null /* the declared type of the value represented as a string in StringValue*/
)
AS
BEGIN
DECLARE
@FirstObject INT, –the index of the first open bracket found in the JSON string
@OpenDelimiter INT,–the index of the next open bracket found in the JSON string
@NextOpenDelimiter INT,–the index of subsequent open bracket found in the JSON string
@NextCloseDelimiter INT,–the index of subsequent close bracket found in the JSON string
@Type NVARCHAR(10),–whether it denotes an object or an array
@NextCloseDelimiterChar CHAR(1),–either a ‘}’ or a ‘]’
@Contents NVARCHAR(MAX), –the unparsed contents of the bracketed expression
@Start INT, –index of the start of the token that you are parsing
@end INT,–index of the end of the token that you are parsing
@param INT,–the parameter at the end of the next Object/Array token
@EndOfName INT,–the index of the start of the parameter at end of Object/Array token
@token NVARCHAR(200),–either a string or object
@value NVARCHAR(MAX), — the value as a string
@SequenceNo int, — the sequence number within a list
@name NVARCHAR(200), –the name as a string
@parent_ID INT,–the next parent ID to allocate
@lenJSON INT,–the current length of the JSON String
@characters NCHAR(36),–used to convert hex to decimal
@result BIGINT,–the value of the hex symbol being parsed
@index SMALLINT,–used for parsing the hex value
@Escape INT –the index of the next escape character
DECLARE @Strings TABLE /* in this temporary table we keep all strings, even the names of the elements, since they are ‘escaped’ in a different way, and may contain, unescaped, brackets denoting objects or lists. These are replaced in the JSON string by tokens representing the string */
(
String_ID INT IDENTITY(1, 1),
StringValue NVARCHAR(MAX)
)
SELECT–initialise the characters to convert hex to ascii
@characters=’0123456789abcdefghijklmnopqrstuvwxyz’,
@SequenceNo=0, –set the sequence no. to something sensible.
/* firstly we process all strings. This is done because [{} and ] aren’t escaped in strings, which complicates an iterative parse. */
@parent_ID=0;
WHILE 1=1 –forever until there is nothing more to do
BEGIN
SELECT
@start=PATINDEX(‘%[^a-zA-Z][“]%’, @json collate SQL_Latin1_General_CP850_Bin);–next delimited string
IF @start=0 BREAK –no more so drop through the WHILE loop
IF SUBSTRING(@json, @start+1, 1)='”‘
BEGIN –Delimited Name
SET @start=@Start+1;
SET @end=PATINDEX(‘%[^\][“]%’, RIGHT(@json, LEN(@json+’|’)-@start) collate SQL_Latin1_General_CP850_Bin);
END
IF @end=0 –no end delimiter to last string
BREAK –no more
SELECT @token=SUBSTRING(@json, @start+1, @end-1)
–now put in the escaped control characters
SELECT @token=REPLACE(@token, FROMString, TOString)
FROM
(SELECT
‘\”‘ AS FromString, ‘”‘ AS ToString
UNION ALL SELECT ‘\\’, ‘\’
UNION ALL SELECT ‘\/’, ‘/’
UNION ALL SELECT ‘\b’, CHAR(08)
UNION ALL SELECT ‘\f’, CHAR(12)
UNION ALL SELECT ‘\n’, CHAR(10)
UNION ALL SELECT ‘\r’, CHAR(13)
UNION ALL SELECT ‘\t’, CHAR(09)
) substitutions
SELECT @result=0, @escape=1
–Begin to take out any hex escape codes
WHILE @escape>0
BEGIN
SELECT @index=0,
–find the next hex escape sequence
@escape=PATINDEX(‘%\x[0-9a-f][0-9a-f][0-9a-f][0-9a-f]%’, @token collate SQL_Latin1_General_CP850_Bin)
IF @escape>0 –if there is one
BEGIN
WHILE @index<4 –there are always four digits to a \x sequence
BEGIN
SELECT –determine its value
@result=@result+POWER(16, @index)
*(CHARINDEX(SUBSTRING(@token, @escape+2+3-@index, 1),
@characters)-1), @index=@index+1 ;
END
— and replace the hex sequence by its unicode value
SELECT @token=STUFF(@token, @escape, 6, NCHAR(@result))
END
END
–now store the string away
INSERT INTO @Strings (StringValue) SELECT @token
— and replace the string with a token
SELECT @JSON=STUFF(@json, @start, @end+1,
‘@string’+CONVERT(NVARCHAR(5), @@identity))
END
— all strings are now removed. Now we find the first leaf.
WHILE 1=1 –forever until there is nothing more to do
BEGIN
SELECT @parent_ID=@parent_ID+1
–find the first object or list by looking for the open bracket
SELECT @FirstObject=PATINDEX(‘%[{[[]%’, @json collate SQL_Latin1_General_CP850_Bin)–object or array
IF @FirstObject = 0 BREAK
IF (SUBSTRING(@json, @FirstObject, 1)='{‘)
SELECT @NextCloseDelimiterChar=’}’, @type=’object’
ELSE
SELECT @NextCloseDelimiterChar=’]’, @type=’array’
SELECT @OpenDelimiter=@firstObject
WHILE 1=1 –find the innermost object or list…
BEGIN
SELECT
@lenJSON=LEN(@JSON+’|’)-1
–find the matching close-delimiter proceeding after the open-delimiter
SELECT
@NextCloseDelimiter=CHARINDEX(@NextCloseDelimiterChar, @json,
@OpenDelimiter+1)
–is there an intervening open-delimiter of either type
SELECT @NextOpenDelimiter=PATINDEX(‘%[{[[]%’,
RIGHT(@json, @lenJSON-@OpenDelimiter)collate SQL_Latin1_General_CP850_Bin)–object
IF @NextOpenDelimiter=0
BREAK
SELECT @NextOpenDelimiter=@NextOpenDelimiter+@OpenDelimiter
IF @NextCloseDelimiter<@NextOpenDelimiter
BREAK
IF SUBSTRING(@json, @NextOpenDelimiter, 1)='{‘
SELECT @NextCloseDelimiterChar=’}’, @type=’object’
ELSE
SELECT @NextCloseDelimiterChar=’]’, @type=’array’
SELECT @OpenDelimiter=@NextOpenDelimiter
END
—and parse out the list or name/value pairs
SELECT
@contents=SUBSTRING(@json, @OpenDelimiter+1,
@NextCloseDelimiter-@OpenDelimiter-1)
SELECT
@JSON=STUFF(@json, @OpenDelimiter,
@NextCloseDelimiter-@OpenDelimiter+1,
‘@’+@type+CONVERT(NVARCHAR(5), @parent_ID))
WHILE (PATINDEX(‘%[A-Za-z0-9@+.e]%’, @contents collate SQL_Latin1_General_CP850_Bin))<>0
BEGIN
IF @Type=’Object’ –it will be a 0-n list containing a string followed by a string, number,boolean, or null
BEGIN
SELECT
@SequenceNo=0,@end=CHARINDEX(‘:’, ‘ ‘+@contents)–if there is anything, it will be a string-based name.
SELECT @start=PATINDEX(‘%[^A-Za-z@][@]%’, ‘ ‘+@contents collate SQL_Latin1_General_CP850_Bin)–AAAAAAAA
SELECT @token=SUBSTRING(‘ ‘+@contents, @start+1, @End-@Start-1),
@endofname=PATINDEX(‘%[0-9]%’, @token collate SQL_Latin1_General_CP850_Bin),
@param=RIGHT(@token, LEN(@token)-@endofname+1)
SELECT
@token=LEFT(@token, @endofname-1),
@Contents=RIGHT(‘ ‘+@contents, LEN(‘ ‘+@contents+’|’)-@end-1)
SELECT @name=stringvalue FROM @strings
WHERE string_ID=@param –fetch the name
END
ELSE
SELECT @Name=null,@SequenceNo=@SequenceNo+1
SELECT
@end=CHARINDEX(‘,’, @contents)– a string-token, object-token, list-token, number,boolean, or null
IF @end=0
SELECT @end=PATINDEX(‘%[A-Za-z0-9@+.e][^A-Za-z0-9@+.e]%’, @Contents+’ ‘ collate SQL_Latin1_General_CP850_Bin)
+1
SELECT
@start=PATINDEX(‘%[^A-Za-z0-9@+.e][A-Za-z0-9@+.e]%’, ‘ ‘+@contents collate SQL_Latin1_General_CP850_Bin)
–select @start,@end, LEN(@contents+’|’), @contents
SELECT
@Value=RTRIM(SUBSTRING(@contents, @start, @End-@Start)),
@Contents=RIGHT(@contents+’ ‘, LEN(@contents+’|’)-@end)
IF SUBSTRING(@value, 1, 7)=’@object’
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, Object_ID, ValueType)
SELECT @name, @SequenceNo, @parent_ID, SUBSTRING(@value, 8, 5),
SUBSTRING(@value, 8, 5), ‘object’
ELSE
IF SUBSTRING(@value, 1, 6)=’@array’
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, Object_ID, ValueType)
SELECT @name, @SequenceNo, @parent_ID, SUBSTRING(@value, 7, 5),
SUBSTRING(@value, 7, 5), ‘array’
ELSE
IF SUBSTRING(@value, 1, 7)=’@string’
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, ValueType)
SELECT @name, @SequenceNo, @parent_ID, stringvalue, ‘string’
FROM @strings
WHERE string_ID=SUBSTRING(@value, 8, 5)
ELSE
IF @value IN (‘true’, ‘false’)
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, ValueType)
SELECT @name, @SequenceNo, @parent_ID, @value, ‘boolean’
ELSE
IF @value=’null’
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, ValueType)
SELECT @name, @SequenceNo, @parent_ID, @value, ‘null’
ELSE
IF PATINDEX(‘%[^0-9]%’, @value collate SQL_Latin1_General_CP850_Bin)>0
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, ValueType)
SELECT @name, @SequenceNo, @parent_ID, @value, ‘real’
ELSE
INSERT INTO @hierarchy
(NAME, SequenceNo, parent_ID, StringValue, ValueType)
SELECT @name, @SequenceNo, @parent_ID, @value, ‘int’
if @Contents=’ ‘ Select @SequenceNo=0
END
END
INSERT INTO @hierarchy (NAME, SequenceNo, parent_ID, StringValue, Object_ID, ValueType)
SELECT ‘-‘,1, NULL, ”, @parent_ID-1, @type
—
RETURN
END
GO





 Buradaki resimde ise başka sayaçlar da eklenmiş durumda.
Buradaki resimde ise başka sayaçlar da eklenmiş durumda.