

SQL Server’da hatta tüm veritabanlarında Index’in ne kadar önemli olduğunu bilmeyen yoktur sanırım.
Index performansı ile alakalı şöyle bir örnek vereyim.
128 milyon satırlı bir tabloda index yoksa aradığınız bir satırı bulmak için 128 milyon işlem yaparsınız.
Oysa index varsa binary search mantığı ile sistem sürekli ikiye bölme mantığı ile gittiği için aşağıda gördüğünüz gibi 27 işlemde işi bitirir.
1) 128,000,000 /2
2) 64,000,000 /2
3) 32,000,000 /2
4) 16,000,000 /2
5) 8,000,000 /2
6) 4,000,000 /2
7) 2,000,000 /2
8) 1,000,000 /2
9) 500,000 /2
10) 250,000 /2
11) 125,000 /2
12) 62,500 /2
13) 31,250 /2
14) 15,625 /2
15) 7,813 /2
16) 3,906 /2
17) 1,953 /2
18) 977 /2
19) 488 /2
20) 244 /2
21) 122 /2
22) 61 /2
23) 31 /2
24) 15 /2
25) 8 /2
26) 4 /2
27) 2 /2
Satır sayısı iki katına çıktığında yani 256 milyon olduğunda ise index olmadan arama işlemi 256 milyona çıkarken index li arama işlemi 28 adımda gerçekleşir.
1) 256,000,000 /2
2) 128,000,000 /2
3) 64,000,000 /2
4) 32,000,000 /2
5) 16,000,000 /2
6) 8,000,000 /2
7) 4,000,000 /2
8) 2,000,000 /2
9) 1,000,000 /2
10) 500,000 /2
11) 250,000 /2
12) 125,000 /2
13) 62,500 /2
14) 31,250 /2
15) 15,625 /2
16) 7,813 /2
17) 3,906 /2
18) 1,953 /2
19) 977 /2
20) 488 /2
21) 244 /2
22) 122 /2
23) 61 /2
24) 31 /2
25) 15 /2
26) 8 /2
27) 4 /2
28) 2 /2
Dediğim gibi indexi bilen bilir de bu hesabı bilmeyenler vardır belki diye bu açıklamayı yaptım.
Indexler yaşayan varlıklar. Yeni kayıtlar eklendiğinde, kayıtlar silindiğinde ya da güncelleme işlemi yapıldığında haliyle bu indexler bozuluyor ve belli zaman aralıklarında bunları güncellemek gerekiyor. Bunun yolu da çok basit. 2 dakikada bu işi yapacak bir planı kod yazmadan oluşturabilirsiniz.
Bu düzeltme işlemi bazen uzun sürüyor ve sistemi kilitliyor ve durdurmak zorunda kalıyorusunuz. Siz hangi tablonun indexlerinin yapıldığını hangi tablonun yapılmadığını bilemiyorsunuz.
Ayrıca hangi tablo indexten önce ne kadar bozuktu, indexten sonra ne kadar düzeldi onu da bilmiyorsunuz.
Yine hangi tablodaki index düzeltme işleminin ne kadar sürdüğünü de bilmiyorsunuz.
İşte bu sorunlara çözüm olması amacı ile bir stored procedure yazdım ve onu burada paylaşmak istiyorum.
Bunun için index işlemini loglamak amacı ile bir veritabanı ve bir tablo oluşturuyoruz.
Örneğin ben burada database i BT diye oluşturdum.
Siz de aşağıdaki script ile oluşturabilirsiniz.
use BT
CREATE TABLE [dbo].[TBLINDEXLOG](
[ID] [int] IDENTITY(1,1) NOT NULL,
[SEQID] [int] NULL,
[DBNAME] [varchar](50) NULL,
[TABLENAME] [varchar](250) NULL,
[BEGDATE] [datetime] NOT NULL,
[ENDDATE] [datetime] NULL,
[DURATION] [int] NULL,
[FRAGMANTATIONBEFORE] [float] NULL,
[FRAGMANTATIONAFTER] [nchar](10) NULL,
[ROWCOUNT_] [int] NULL,
[DATASIZEBEFORE] [int] NULL,
[INDEXSIZEBEFORE] [int] NULL,
[TABLESIZEBEFORE] [int] NULL,
[DATASIZEAFTER] [int] NULL,
[INDEXSIZEAFTER] [int] NULL,
[TABLESIZEAFTER] [int] NULL,
CONSTRAINT [PK_TBLINDEXLOG] PRIMARY KEY CLUSTERED
(
[ID] ASC
) )
Burada alanları şu şekilde açıklayabiliriz.
ID:Otomatik artan alan
SEQID:Toplu olarak yapılan index işleminde her tablo loglanacağı için bu toplu işlemi takip etme adına koyduğumuz SEQUENCEID değeri.
DBNAME:Hangi database’de index düzeltme yapıyorsak onun bilgisi
TABLENAME:Index düzeltme yaptğımız tablonun adı.
BEGDATE:Index başlama zamanı
ENDDATE:Index bitme zamanı
DURATION:Index düzeltme süresi (ENDDATE-BEGDATE)
FRAGMANTATIONBEFORE:Index yapmadan önceki indexlerin bozukluk oranı.
FRAGMANTATIONAFTER: Index yaptıktan sonraki indexlerin bozukluk oranı.
ROWCOUNT_:Tablodaki satır sayısı
DATASIZEBEFORE:Index yapmadan önce tabloda datanın kapladığı alan
INDEXSIZEBEFORE:Index yapmadan önce tabloda indexlerin kapladığı alan
TABLESIZEBEFORE: DATASIZEBEFORE+ INDEXSIZEBEFORE
DATASIZEAFTER:Index yaptıktan sonra tabloda datanın kapladığı alan
INDEXSIZEAFTER:Index yaptıktan sonra tabloda indexlerin kapladığı alan
TABLESIZEAFTER: DATASIZEAFTER+ INDEXSIZEAFTER
Procedure ümüz ize aşağıdaki gibi. Gördüğümüz gibi içerisine iki parametre alıyor biri tablo adı. Yani ben sadece bir tabloyu ya da adı “LG_“ ile başlayan tabloları index yap diyebilirim.
İkincisi ise fill factor. Bunu da bilen bilir. İdeali 70-80 gibi değerler vermektir ama duruma göre farklı değerler de verebilirsiniz.
CREATE PROC [dbo].[SPREINDEX]
@TABLENAME AS VARCHAR(1000)=’%’,
@FILLFACTOR AS INT=70
AS
DECLARE @ID AS INT
DECLARE @SEQID AS INT
DECLARE @BEGDATE AS DATETIME
DECLARE @ENDDATE AS DATETIME
DECLARE @DURATION AS INT
DECLARE @ROWCOUNT AS INT
DECLARE @DATASIZEBEFORE INT
DECLARE @INDEXSIZEBEFORE AS INT
DECLARE @TABLESIZEBEFORE AS INT
DECLARE @DATASIZEAFTER INT
DECLARE @INDEXSIZEAFTER AS INT
DECLARE @TABLESIZEAFTER AS INT
DECLARE @FRAGMANTATIONBEFORE AS FLOAT
DECLARE @FRAGMANTATIONAFTER AS FLOAT
SELECT @SEQID=MAX(SEQID)+1 FROM BT.DBO.TBLINDEXLOG
SET @SEQID=ISNULL(@SEQID,1)
CREATE TABLE #T (NAME VARCHAR(200),ROWS INT,RESERVED VARCHAR(100),DATA VARCHAR(100),INDEX_SIZE VARCHAR(100),UNUSED VARCHAR(100))
DECLARE @TABLENAME2 AS VARCHAR(1000)
DECLARE CRS CURSOR FOR SELECT NAME FROM SYSOBJECTS WHERE XTYPE=’U’ AND NAME LIKE @TABLENAME
OPEN CRS
FETCH NEXT FROM CRS INTO @TABLENAME2
WHILE @@FETCH_STATUS=0
BEGIN
SET @BEGDATE=GETDATE()
TRUNCATE TABLE #T
INSERT INTO #T
EXEC SP_SPACEUSED @TABLENAME2
SELECT @ROWCOUNT=ROWS
,@TABLESIZEBEFORE=CONVERT(INT,REPLACE(RESERVED,’ KB’,”))
,@DATASIZEBEFORE=CONVERT(INT,REPLACE(DATA,’ KB’,”))
,@INDEXSIZEBEFORE=CONVERT(INT,REPLACE(INDEX_SIZE,’ KB’,”))
FROM #T
SELECT @FRAGMANTATIONBEFORE=avg(avg_fragmentation_in_percent) FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID(@TABLENAME2), NULL, NULL , ‘LIMITED’)
— WHERE index_type_desc <>’CLUSTERED INDEX’
INSERT INTO BT.DBO.TBLINDEXLOG
(SEQID, TABLENAME,DBNAME, BEGDATE,ROWCOUNT_,DATASIZEBEFORE,INDEXSIZEBEFORE,TABLESIZEBEFORE,FRAGMANTATIONBEFORE)
VALUES
(@SEQID, @TABLENAME2,DB_NAME(), @BEGDATE,@ROWCOUNT,@DATASIZEBEFORE,@INDEXSIZEBEFORE,@TABLESIZEBEFORE,@FRAGMANTATIONBEFORE)
SET @ID=@@IDENTITY
DECLARE @SQL AS NVARCHAR(MAX)
SET @SQL=’ALTER INDEX ALL ON ‘+@TABLENAME2+’ REBUILD WITH (FILLFACTOR=’+CONVERT(VARCHAR,@FILLFACTOR)+’)’
EXEC SP_EXECUTESQL @SQL
TRUNCATE TABLE #T
INSERT INTO #T
EXEC SP_SPACEUSED @TABLENAME2
SELECT @ROWCOUNT=ROWS
,@TABLESIZEAFTER=CONVERT(INT,REPLACE(RESERVED,’ KB’,”))
,@DATASIZEAFTER=CONVERT(INT,REPLACE(DATA,’ KB’,”))
,@INDEXSIZEAFTER=CONVERT(INT,REPLACE(INDEX_SIZE,’ KB’,”))
FROM #T
SET @ENDDATE=GETDATE()
SET @DURATION=DATEDIFF(SECOND,@BEGDATE,@ENDDATE)
SELECT @FRAGMANTATIONAFTER=avg(avg_fragmentation_in_percent) FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID(@TABLENAME2), NULL, NULL , ‘LIMITED’)
WHERE index_type_desc <>’CLUSTERED INDEX’
SET @SQL=’UPDATE STATISTICS ‘+@TABLENAME2
EXEC SP_EXECUTESQL @SQL
UPDATE BT.DBO.TBLINDEXLOG SET
ENDDATE=@ENDDATE, DURATION=@DURATION, DATASIZEAFTER=@DATASIZEAFTER, INDEXSIZEAFTER=@INDEXSIZEAFTER,
TABLESIZEAFTER=@TABLESIZEAFTER,
FRAGMANTATIONAFTER=@FRAGMANTATIONAFTER
WHERE ID=@ID
FETCH NEXT FROM CRS INTO @TABLENAME2
END
CLOSE CRS
DEALLOCATE CRS
DROP TABLE #T
Ben bu procedure ü kendi test ortamımda çalıştırdım ve 58 sn sürdü.
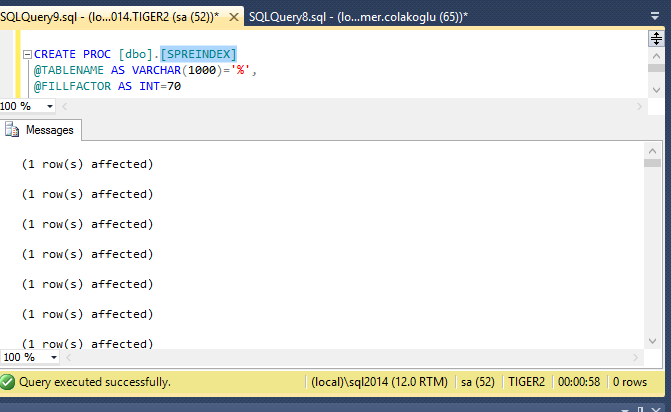
Şimdi sonuçlara bakalım.
Aşağıdaki resim en çok bozuk index olan tabloları gösteriyor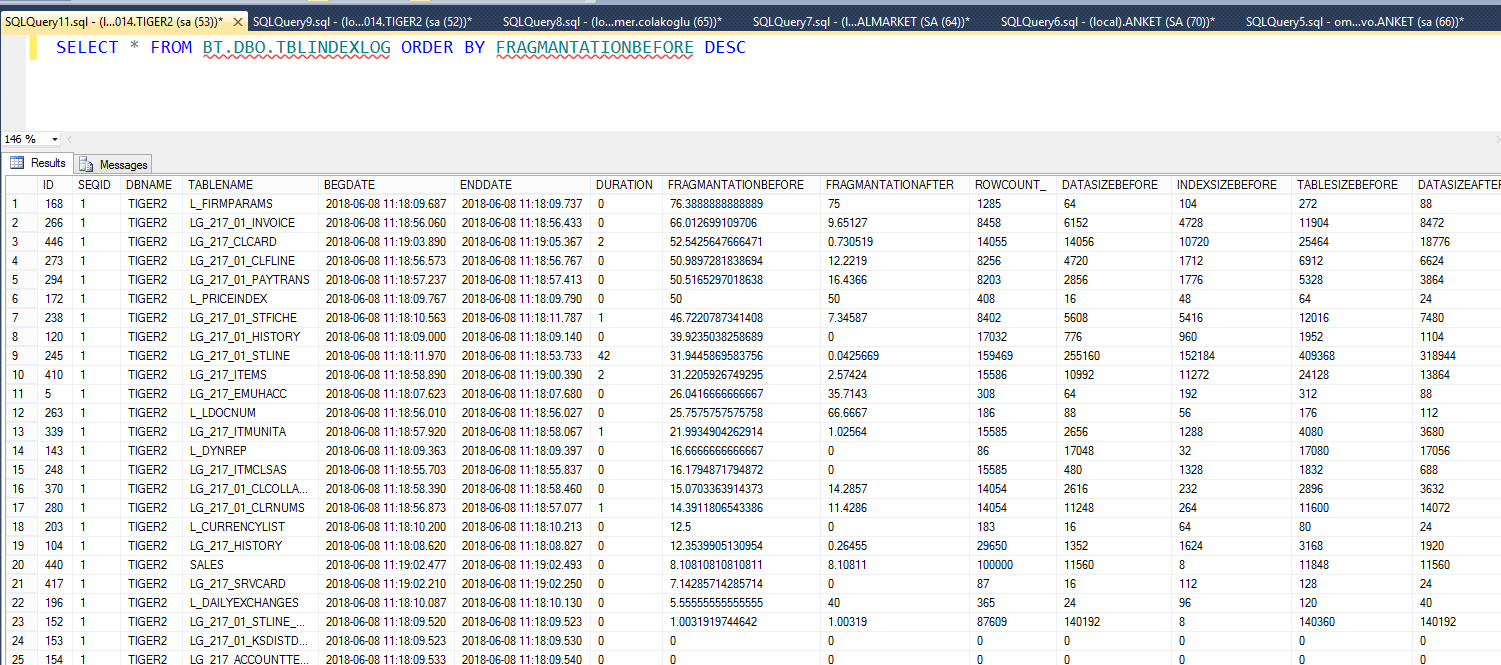
Bu resim de en çok satır sayıları olan tabloları incelememizi sağlıyor. Örneğin burada LG_217_01_STLINE tablosunu inceleyelim
%31 fragmante olmuş yani indexler %31 oranında bozuk.
159.469 satır var
Index süresi 42 sn sürmüş.
Tablo boyutu indexten sonra 409.368 KB’tan 492.056’a çıkmış. Bu büyüme Fill factor değerinden kaynaklanıyor.
Bu sorgu da işlemin toplam ne kadar sürdüğünü söylüyor. Burada saniyeler yuvarlandığı için 53 olarak getirmiş.
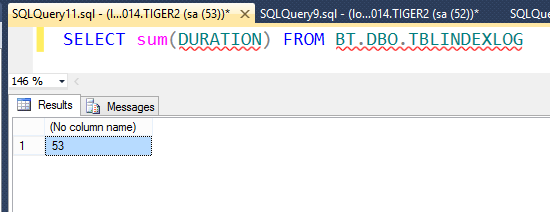
Bu procedure ü de örneğin haftada bir çalışacak bir job haline getirirsek alın size Index maintanance plan.
Umarım anlaşılabilir bir makale olmuştur. Çünkü gerçekten veritabanı ile uğraşanlar için büyük kolaylık sağlıyor.
Başka bir yazıda görüşmek üzere.

Süper.
BeğenBeğen
Hocam merhaba, bu konularda yeniyim. Udemy üzerinizden eğitimizi alıyorum. Şimdi burada LG ile başlayan tablolar nasıl yazılır acaba ? Bildiğiniz gibi Logo veri tabanında o kadar çok LG ile başlayan tablo var ki. Tek tek yapmak çok çok zor. Bu yüzden soruyorum.
BeğenBeğen