Merhaba,
Bu yazıda veri bilimi konusunda sıklıkla yapılan çalışmalardan RFM konusunun SQL Server üzerinde T-SQL kodları yazarak nasıl yapılacağını uygulamalı şekilde anlatacağım.
Konuyu bilmeyenler için RFM Analizi ne demek biraz bahsedelim.
RFM nedir?
Recency, Frequency, Monetary kelimelerinin baş harflerinden oluşup, bu üç metriğin hesaplanmasından sonra birleştirilmesiyle meydana gelen bir skordur. Müşterilerin mevcut durumunun analiz edilip, bu skorlara göre segmentlere ayrılmasına yardımcı olur.
Recency: Müşterinin ne kadardır websitesinden/mağazadan hizmet aldığı, ne zamandır bize üye olduğu gibi bilgileri verir. Hesaplanması genellikle, bugünden son üyelik tarihi/son sipariş tarihinin çıkartılmasıyla elde edilir.
Frequency: Müşterinin ne sıklıkla alışveriş yaptığını, ne sıklıkla siteye giriş yaptığını gösteren metriktir. Genellikle sipariş numarası/sipariş kodunun saydırılmasıyla sonuç verir.
Monetary: Müşterinin harcamalarının toplamıdır. E-ticaret sitesine getirdiği ciro, aldığı hizmetler sonrası toplanan getiri olarak da tanımlanabilir. Ciro tanımı ne ise, müşteri bazında hayatı boyunca yapılan harcamalar toplanarak hesaplanır.
Bu metrikler belirlendikten sonra, metrik bazında müşteri verisi 5 eşit parçaya ayrılır. Sonrasında bu rakamlar bir araya getirilerek bir RFM skoru atanır.
Kaynak: https://www.veribilimiokulu.com/rfm-analizi-ile-musteri-segmentasyonu/
RFM analizi bir satış veriseti üzerinde çalışarak elde edilir ve yapılan çalışma sonucunda bir müşteri sınıflandırma işlemi gerçekleştirilir.
Elde etmek istediğimiz tablo aşağıdaki gibidir.

Burada alanların açıklamaları aşağıdaki gibidir.
CustomerID:Sınıflandırılamak istenen müşterinin ID’sidir. Burada müşteri kodu, müşteri adı gibi bilgiler de olabilir.
LastInvoiceDate:Müşterinin son alışveriş yaptığı tarih ve zaman bilgisini tutar. Bu bilgi bizim Recency değerimizi hesaplamak için kullanacağımız bir alandır.
Recency: Müşterinin en son ne zaman alışveriş yaptığı bilgisinin bir metriğidir. Bugün-Son alışveriş tarihi olarak hesaplanır.
Frequency: Müşterinin ne sıklıkta alışveriş yaptığı bilgisidir. Burada fatura numarası ya da sipariş numarası gibi alanlar distinct olarak sayılarak bulunur.
Monetary: Müşterinin harcamalarının toplamıdır. Yani toplamda bir müşteri parasal olarak ne kadarlık alışveriş yapıyor onun karşılığıdır.
Recency_Scale: Elde edilen Recency değerinin 1-5 arasına sıkıştırılmış halidir. Daha açıklayıcı anlatmak gerekirse, diyelim 100 satır kaydımız var.
100/5=20
Demek ki tüm veriyi Receny değerine göre sıralar isek
Sıralamada
1-20 arası=1
21-40 arası=2
41-60 arası=3
61-80 arası=4
81-100 arası=5 olacak şekilde bir yeniden boyutlandırma (Scale) işlemi yapılmaktadır.
Frequency _Scale: Elde edilen Frequency değerinin 1-5 arasına sıkıştırılmış halidir.
Monetary _Scale: Elde edilen Monetary değerinin 1-5 arasına sıkıştırılmış halidir.
Segment: Elde edilen Recency_Scale, Frequency _Scale, Monetary _Scale değerlerine göre belli bir formül ile müşterinin sınıflandırılmasıdır. Bu sınıflandırmada müşteriler Need_Attention, Cant_Loose,At_Risk,Potential_Loyalists, Loyal_Customers, About_to_Sleep,Hibernating,New_Customers, Promising, Champions
Sınıflarından birine göre sınıflandırılır.
Hadi şimdi işe koyulalım ve RFM analizi için önce veri setimizi indirelim.
Verisetimiz https://archive.ics.uci.edu/ml/machine-learning-databases/00502/online_retail_II.xlsx adresindeki online_retail_II.xlsx isminde bir excel dosyası.
Bu dosyayı indirelim.
Görüldüğü gibi dosyamız bu şekilde bir görünüme sahip.

Dosyada 2009-2010 ve 2010-2011 yılına ait satış verileri bulunmakta. Biz uygulamamızda bu iki veriden birini seçip çalışacağız. İstenirse bu iki veri birleştirilebilir. Biz şimdilik Year 2010-2011 verilerini dikkate alalım.
Bu sayfaya baktığımızda 540.457 satırlık bir verinin olduğunu görüyoruz. Tabi burada bir müşteriye ait birden fazla fatura var ve bir faturanın altında da birden fazla ürün satırı var. O yüzden satır sayısı bu kadar fazla.
Şimdi kolonlardan biraz bahsedelim.
Invoice: Fatura numarası
StockCode: Satılan ürünün kodu
Description: Satılan ürünün adı
Quantity: Ürün adedi
InvoiceDate: Fatura tarihi
Price: Ürün birim fiyatı
Customer Id: Müşteri numarası
Country: Müşterinin ülkesi
Şimdi bu excel dosyamızı da gördüğümüze göre artık SQL Server platformuna geçme vakti. Malum yazımızın konusu RFM analizini MSSQL üzerinde gerçekleştirme.
İlk iş bu excel datasını SQL Server’a aktarmak.
Bunun için SQL Server üzerinde RFM isimli bir veritabanı oluşturalım.
Bunun için aşağıdaki gibi New Database diyerek yeni bir database oluşturabiliriz.


RFM isimli database imiz oluştu.

Şimdi bu database e excel dosyasındaki veriyi import edeceğiz. Bunun için database üzerinde sağ tıklayarak Task>Import Data diyoruz.





Next butonuna bastığımızda aşağıdaki hatayı alıyorsanız merak etmeyin çözümü var. Hata almıyorsanız bu kısmı okumasanız da olur.
Bu hatada Microsoft.Ace.Oledb.12.0 provider hatasını görüyoruz. Bu hatayı gidermek için Microsoft Access Database Engine’i bilgisayarınıza yüklemeniz gerekiyor. Bunun için aşağıdaki linki kullanabilirsiniz.
https://www.microsoft.com/en-us/download/confirmation.aspx?id=13255
Kurulumu next diyerek default ayarları ile yapabilirsiniz.


Ve kurulum tamamlandı.

Şimdi tekrardan Excel dosyamızı import ediyoruz. Import/Export wizard da kaynak olarak Excel dosyamızı göstermiştik. Hedef olarak ise SQL Server’ı göstereceğiz.

Bağlanacağımız SQL Server’ı seçiyor ve kullanıcı bilgilerini giriyoruz. Benim kullandığım SQL Server kendi makinem olduğu için server name kısmına localhost yazıyor, kullanıcı bilgilerine de Windows authentication’ı işaretliyoruz. Siz de kendi bağlandığınız SQL Server bilgilerini girebilirsiniz.

Copy data from one or more tables or views seçeneğini seçiyoruz.

Next dediğimizde karşımıza aşağıdaki ekran geliyor. Source kısmında Excel dosyasındaki sheet adı, Destination kısmında ise SQL Server’da oluşturacağımız tablonun adı geliyor. Burayı elle değiştirebiliyoruz. 2010-211 yılları arasındaki veriyi kullanmayı tercih ediyoruz.

SQL Server’a aktaracağımız tablonun adını ONLINERETAIL_2010 olarak değiştiriyoruz.

Burada Next deyip devam edebiliriz ancak Edit Mappings butonuna basıp yeni oluşan tablonun alanlarını ve veri tiplerini de görebiliriz. Edit Mappings butonuna basında biraz bekleyebilirsiniz. Zira 540.000 satır excel dosyasını okurken ki bekletme bu. Bilgisayar dondu diye panik yapmayın. Biraz beklediğinizde aşağıdaki ekranı göreceksiniz. Tablomuzun alanları ve veri tipleri. OK deyip geçebiliriz.

Next dediğimizde Run Immediately seçeneğini işaretliyoruz ve tekrar Next diyoruz.

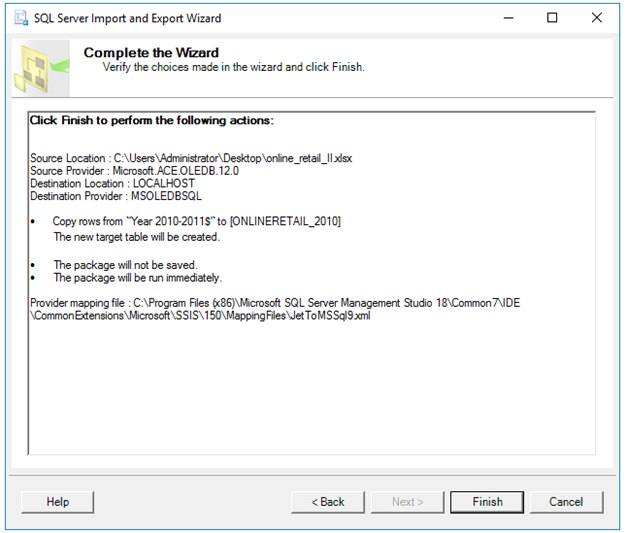
Finish diyoruz ve satırlarımızın aktarılmasını bekliyoruz.
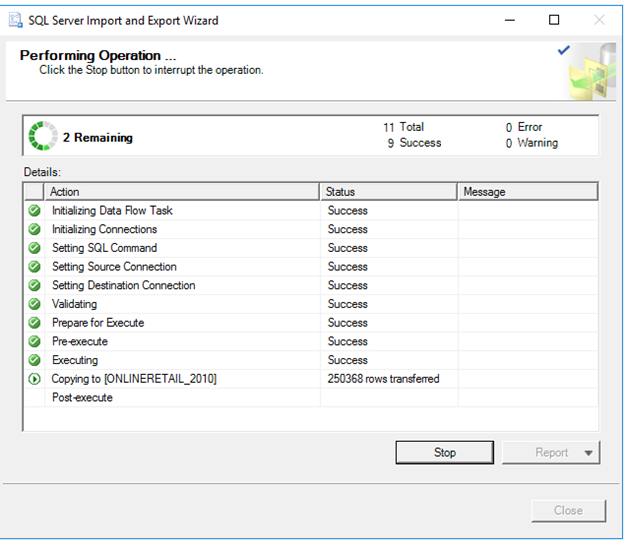
Import işlemi tamamlandı.

Şimdi kontrol edelim.

Artık excel dosyamız veritabanımızda. Buraya kadar ki işlemlerde hata yaşadıysanız. Çalıştığımız veritabanını buradaki linkten indirebilirsiniz.
https://1drv.ms/u/s!AoTudRti4cT8jLEZ3ShT6I2BtteHBw?e=3X4xfl
Artık verilerimizi aktardığımıza göre şimdi RFM analizi işlemlerine başlayabiliriz.
Yazımızın ilk başında RFM analizi sonucunda aşağıdaki gibi bir tablo elde etmek istediğimizden bahsetmiştik.

Bu tabloyu elde etmek için yapılan en büyük hatalardan biri karmaşık SQL cümleleri yazarak tek seferde bu tabloyu elde etmeye çalışmak. Şayet SQL bilginiz de çok iyi değilse geçmiş olsun. SQL ile RFM çalışmanız burada son bulacak büyük ihtimalle.
Şimdi daha basit düşünelim. Sonuçta bir excel tablomuz var. Burada tekrar etmeyen CustomerID ler var ve bu CustomerID lere göre hesaplanan bir takım sütunlar var. O zaman aynı bu mantıkta düşünelim ve bu mantıkta bir tablo oluşturup içine önce CustomerId’leri tekrar etmeyecek şekilde dolduralım. Sonra sırayla diğer alanları hesaplayarak gidelim.
İlk iş bu formatta bir SQL tablosu oluşturmak.
Ekteki gibi bir tablo oluşturuyoruz.



Şimdi her seferinde aynı işlemi yapacağımız için önce tablomuzun içini boşaltacak kodumuzu yazalım.
TRUNCATE TABLE RFM
Sonra tablomuzun için tekrar etmeyecek şekilde CustomerID’ler ile dolduralım. Bunun için kullanacağımız komut,
INSERT INTO RFM (CUSTOMERID)
SELECT DISTINCT [Customer ID] FROM ONLINERETAIL_2010
Burada excelden aktarırken Customer ID kolonunda boşluk olduğu için Customer ID yazarken köşeli parantezler içinde yazıyoruz.

4373 kayıt eklendi dedi. Şimdi tablomuzu kontrol edelim.
Şu anda içinde sadece CustomerId olan diğer alanları null olan 4373 satır kaydımız var.

Şimdi sırayla diğer alanları hesaplayalım. İlk hesaplayacağımız alan LastInvoiceDate. Yani müşterinin yaptığı son satınalma zamanının bulunması. Bu değeri bulacağız ki Recency değeri bu tarih ile şimdiki zamanın farkı üzerinden çıkarılacak ve buna göre bulunacak.
Bu işlem için basit bir update cümlesi kullanabiliriz. Aşağıdaki sorgu her bir müşterinin ONLINERETAIL tablosunda son alışveriş yaptığı zamanı bulup update edecektir.
UPDATE RFM SET LastInvoiceDate=(SELECT MAX(InvoiceDate)
FROM ONLINERETAIL_2010 where [Customer ID]=RFM.CustomerID)

Update ettik. Şimdi de sonuca bakalım. Artık LastInvoiceDate alanımız da güncellenmiş durumda.

Bir sonraki adım Recency değerinin bulunması. Bunun için şimdiki zamandan son alışveriş zamanını çıkarmamız ve tablomuzu güncellememiz gerekiyor. Tıpkı bir excel dosyasında satır satır formül çalıştırır gibi sorgu ile satır satır güncelleme yapacağız.
SQL Server’da iki tarih arasındaki farkı alan komut DateDiff komutu. Burada datediff komutu içine üç parametre alır.
1-Farkı ne türünden alacaksın? Gün, Ay, Yıl…
2-Başlangıç zamanı (LastInvoiceDate)
3-Bitiş zamanı (Şimdiki zaman. Fakat bizim veri setimiz 2011 yılında geçtiği için son zamanı 31.12.2011 olarak alabiliriz.
Şimdi update cümlemizi çalıştıralım.
UPDATE RFM SET Recency=DATEDIFF(DAY,LastInvoiceDate,'20111231')

Sonuca bakalım.

Görüldüğü gibi Recency değerini hesaplatmış durumdayız. Sırada Frequency var. Şimdi de onu aşağıdaki sorgu ile bulalım. Frequency bir kişinin ne sıklıkta alışveriş yaptığı bilgisi idi. Yani fatura numaralarını tekil olarak saydırırsak bu değeri bulabiliriz.
UPDATE RFM SET Frequency=(SELECT COUNT(Distinct Invoice) FROM ONLINERETAIL_2010 where CustomerID=RFM.CustomerID)

Şimdi sonuca tekrar bakalım. Görüldüğü gibi Frequency değerimizi de hesapladık.

Sırada Monatery değerimiz var. Yani bir müşterinin yapmış olduğu toplam alışverişlerin parasal değeri. Bunu da aşağıdaki sql cümlesi ile bulabiliriz. Burada her bir müşteri için birim fiyat ile miktarı çarptırıyoruz.
UPDATE RFM SET Monatery=(SELECT sum(Price*Quantity) FROM ONLINERETAIL_2010 where CustomerID=RFM.CustomerID)
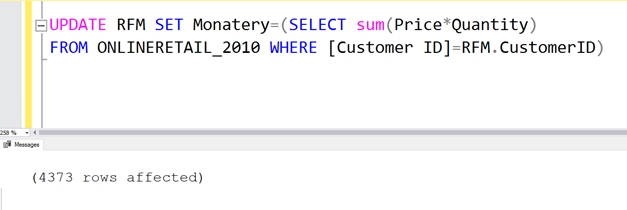
Sonuçlara bakalım. Görüldüğü gibi Monatery değeri de hesaplanmış oldu.

Artık bu aşamadan sonra R,F ve M değerleri için scale değerlerini hesaplamaya sıra geldi. Bunun için tüm değerleri istenilen kolona göre sıralayıp sıra numarasına göre 1-5 arası değerlendirmeye tabi tutmamız gerekiyor. Bunun için kullanacağımız komut ise Rank komutu.
Kullanımı ise aşağıdaki gibi. Kullanımı karışık gelirse copy-paste yapmanız yeterli.
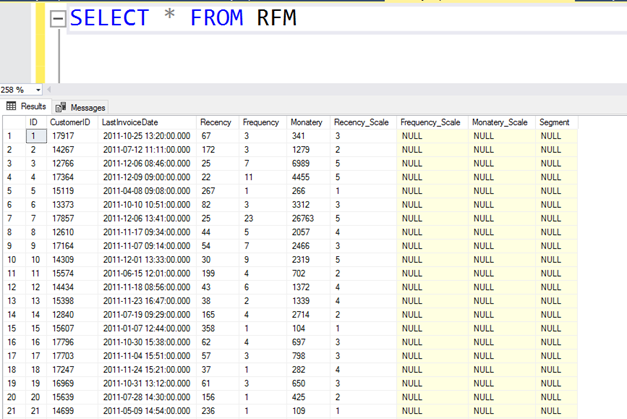
UPDATE RFM SET Recency_Scale=
(
select RANK from
(
SELECT *,
NTILE(5) OVER(
ORDER BY Recency desc) Rank
FROM RFM
) t where CUSTOMERID=RFM. CUSTOMERID)

Sonuçlara baktığımızda artık Recency_Scale değerini de hesaplamış durumdayız.
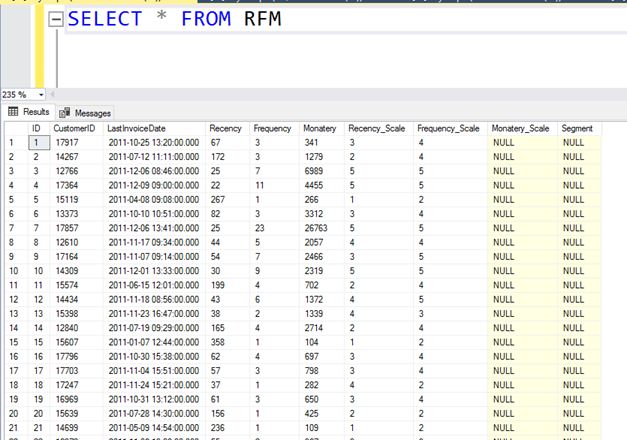
Sırada Frequency_Scale var. Onun için de aşağıdaki komutu kullanıyoruz.
update RFM SET Frequency_Scale=
(
select RANK from
(
SELECT *,
NTILE(5) OVER(
ORDER BY Frequency) Rank
FROM rfm
) T where CUSTOMERID=RFM. CUSTOMERID)

Sonuca bakalım. Görüldüğü gibi Frequency_Scale’ da hesaplanmış durumda.
Ve son olarak Monatey_Scale değeri. Onu da aşağıdaki gibi hesaplıyoruz.
update RFM SET Monatery_Scale=
(
select RANK from
(
SELECT *,
NTILE(5) OVER(
ORDER BY Monatery) Rank
FROM rfm
) t where CustomerID=RFM.CustomerID)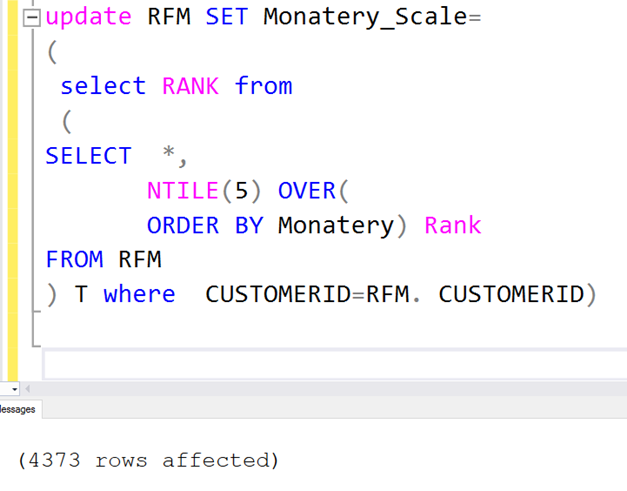
Sonuçlara bakalım. Görüldüğü gibi Monatery_Scale’da hesaplandı.

Son olarak artık tüm değişkenlerimiz hesaplandığına göre geriye bir tek sınıflandırma etiketi kaldı. Onun sorgusu hazır durumda. Aşağıdaki sorguya göre sınıflandırmalar yapılabilir.
UPDATE RFM SET Segment ='Hibernating'
WHERE Recency_Scale LIKE '[1-2]%' AND Frequency_Scale LIKE '[1-2]%'
UPDATE RFM SET Segment ='At_Risk'
WHERE Recency_Scale LIKE '[1-2]%' AND Frequency_Scale LIKE '[3-4]%'
UPDATE RFM SET Segment ='Cant_Loose'
WHERE Recency_Scale LIKE '[1-2]%' AND Frequency_Scale LIKE '[5]%'
UPDATE RFM SET Segment ='About_to_Sleep'
WHERE Recency_Scale LIKE '[3]%' AND Frequency_Scale LIKE '[1-2]%'
UPDATE RFM SET Segment ='Need_Attention'
WHERE Recency_Scale LIKE '[3]%' AND Frequency_Scale LIKE '[3]%'
UPDATE RFM SET Segment ='Loyal_Customers'
WHERE Recency_Scale LIKE '[3-4]%' AND Frequency_Scale LIKE '[4-5]%'
UPDATE RFM SET Segment ='Promising'
WHERE Recency_Scale LIKE '[4]%' AND Frequency_Scale LIKE '[1]%'
UPDATE RFM SET Segment ='New_Customers'
WHERE Recency_Scale LIKE '[5]%' AND Frequency_Scale LIKE '[1]%'
UPDATE RFM SET Segment ='Potential_Loyalists'
WHERE Recency_Scale LIKE '[4-5]%' AND Frequency_Scale LIKE '[2-3]%'
UPDATE RFM SET Segment ='Champions'
WHERE Recency_Scale LIKE '[5]%' AND Frequency_Scale LIKE '[4-5]%'

Sonuçlara bakalım.

Artık tüm müşterilerimizi sınıflandırmış durumdayız. Hatta hangi sınıftan kaç müşteri olduğuna da bakalım.

Vee işlem tamam.
Bu yazımızda SQL Server üzerinde sadece TSQL kodları kullanarak RFM Analizi çalışması yaptık. Çalışmada Online Retail datasını kullandık. Aşağıdaki kodu kullanarak OnlineRetail datasını aktardıktan sonraki tüm RFM hesaplama işlemlerini tek seferde yapabilirsiniz.
Buraya kadar sabırla okuduğunuz için çok teşekkür ederim.
Sağlıcakla…