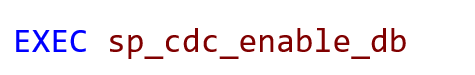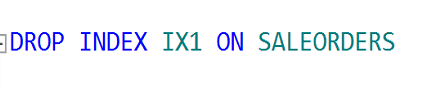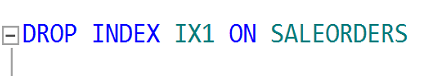In this article, we will learn how to index Json data on SQL Server to perform fast searches.
As we know, Json type data are actually string expressions and can be stored as NVARCHAR(Max) on SQL Server.
The biggest advantage of using Json is that it does not need to be in a structured format in a field and there is no need to make changes to the structure of the database when we want to keep more and different information in the future.
For example, while there is information about the material used in the cover of a product in a product list, there is no need for it in the other. You can add and go. When you want to query, you can only bring what is there.
So, how do we query data in Json format in SQL Server?
The Json commands that we can use with native T-SQL in SQL Server are as follows.
SELECT – FOR Clause
Used to return the output of a query in JSON format.
Example:
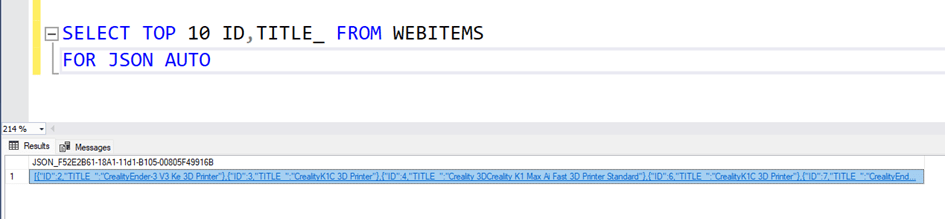
SELECT * FROM TableName FOR JSON AUTO;
Returns TableName data in JSON format.
OPENJSON
Transforms JSON data into SQL Server tables (presents it as chunks and rows/columns).
Example:
SELECT * FROM OPENJSON('{"id":1, "name":"John"}');
Returns JSON in a tabular format: key, value, type.
JSON Functions
What does it do? It includes several functions that make it easy to work with JSON data:
JSON_VALUE()
Used to return the value of a key in JSON. Can only return plain (scalar) values (e.g. number or text).
Usage Example:
SELECT JSON_VALUE('{"id":1, "name":"John"}', '$.name') AS Name;
Features:
Path: The JSON path ($) where the relevant value is located is specified.
It can only return plain values such as text, numbers, etc., it is not used to return objects or arrays.
JSON_QUERY()
Used to return more complex data, such as a subobject or array within JSON.
Example:
SELECT JSON_QUERY('{"id":1, "details":{"age":30, "city":" Newyork "}}', '$.details') AS Details;
Output : {“age”:30, “city”:”Newyork”}
Features:
Used to return an array or object.
Cannot be used for scalar values, JSON_VALUE() is preferred instead.
JSON_MODIFY()
Used to update JSON data, change a value, or add a new value.
Example:
SELECT JSON_MODIFY('{"id":1, "name":"John"}', '$.name', 'Jane') AS UpdatedJson;
Output : {“id”:1, “name”:”Jane”}
Features:
Replaces the value in the specified JSON path.
Can be used to add a new key.
Can be used to delete an existing key (by setting it to NULL).
Summary:
JSON_VALUE() : To get scalar values,
JSON_QUERY() : To get sub-objects or arrays,
JSON_MODIFY() : Used to update, add or delete JSON data.
ISJSON
Checks if a text is valid JSON.
Example:
SELECT ISJSON('{"key":"value"}') AS IsValidJSON; -- returns 1
Returns 1 if valid JSON, 0 otherwise.
JSON_OBJECT (Transact-SQL)
Creates a JSON object from key-value pairs.
Example:
SELECT JSON_OBJECT('id', 1, 'name', 'John') AS JsonObject;
Output : {“id”:1, “name”:”John”}
JSON_ARRAY
Creates an array in JSON format.
Example:
SELECT JSON_ARRAY(1, 'John', 3.14) AS JsonArray;
Output : [1, “John”, 3.14]
With these commands, we can create, edit, query and validate JSON data in SQL Server. JSON support makes it easier to integrate with applications and makes working with unstructured data efficient.
Now let’s talk about the index usage that we need when searching in a data containing JSON.
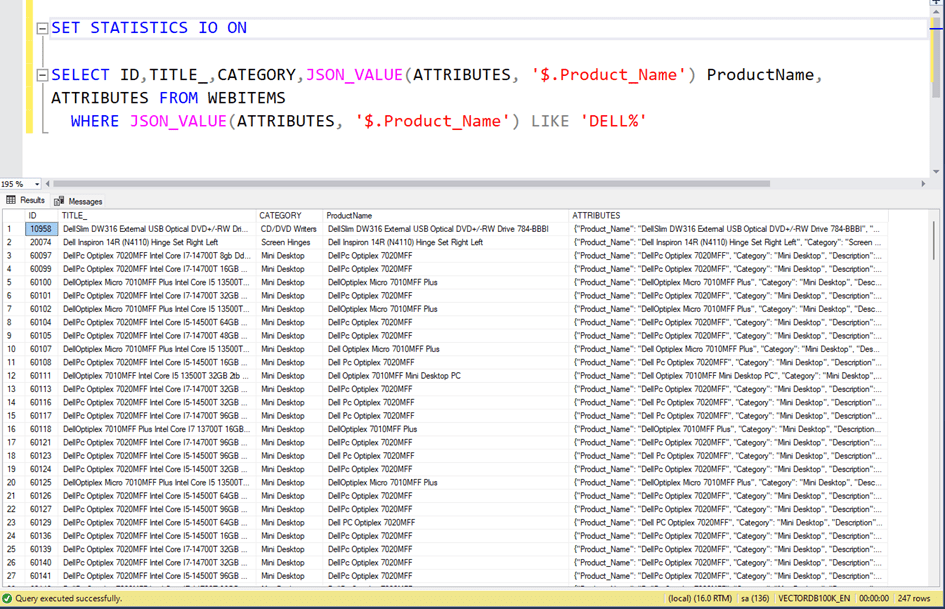
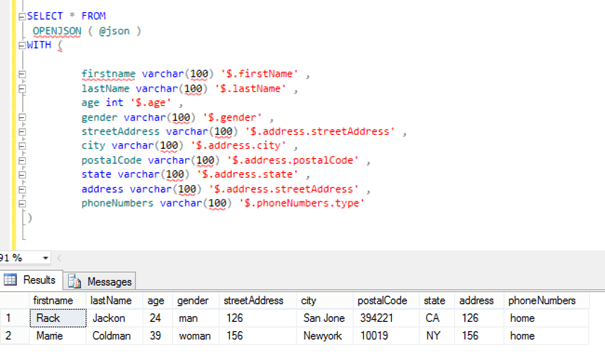
Now we have a dataset like this. 75,959 rows and Json data as an example.
{"Product_Name": "Dell Optiplex Micro 7010MFF Plus", "Category": "Mini Desktop", "Description": "The Dell Optiplex Micro 7010MFF Plus is a powerful mini desktop computer featuring Intel Core i5 13500T processor, 32GB DDR5 RAM, and 4TB SSD storage. It runs on Windows 11 Home operating system and comes in black color. is designed for professional use and offers wireless features, Bluetooth connectivity, and Intel UHD Graphics 770.", "Color": "Black", "Operating System": "Windows 11 Home", "Graphics Card Type": "Internal Video Card ", "Ram Type": "DDR5", "Processor Number": "13500T", "Wireless Feature": "Yes", "Bluetooth": "Yes"}
Here the ATTRIBUTES field is in json format and is kept as NVARCHAR(MAX).
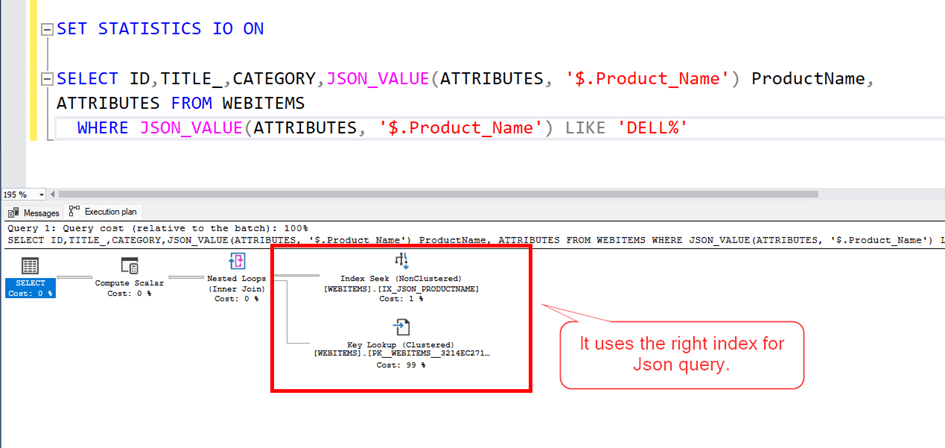
Now, if we want to get products whose Product_Name property starts with ‘Dell%’ in json, we write a query like this. Here we use the JSON_VALUE function.
As you can see, 247 rows of data arrived.
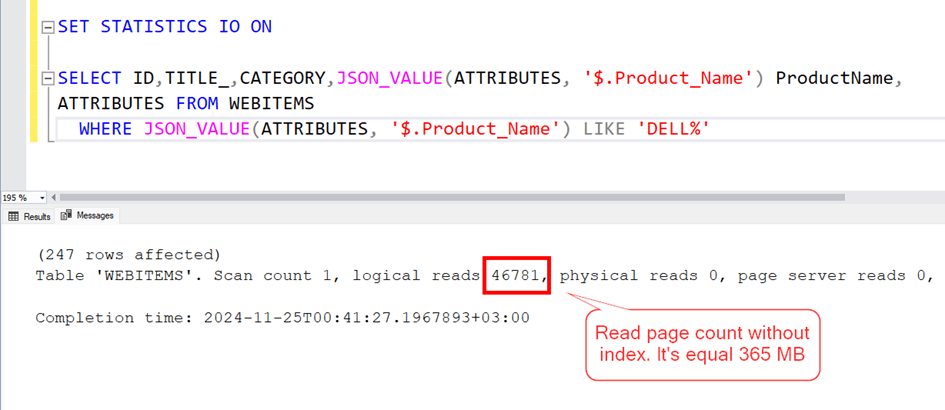
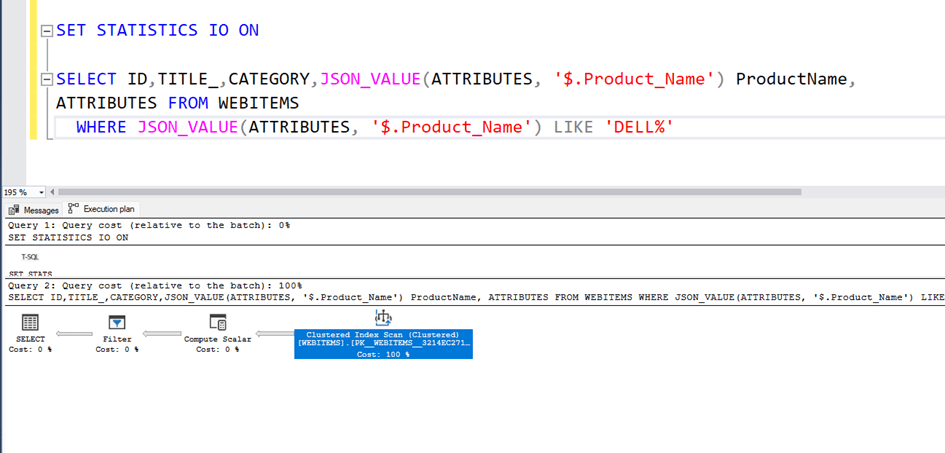
Now let’s look at the execution plan and read count.
As can be seen, the clustered index scans, that is, it scans the entire table, and the total number of pages it reads is 46781. Since each page is 8 KB, this corresponds to a reading of approximately 365 MB.
Now let’s try to put an index on this Json data.
Since Json data is text data, we cannot put an index directly. However, we can add a computed field here and put an index on this field.
For example, if we want to index the Product_Name information in Json,
We can add a field to the table. This field will be a computed field and will automatically get the value of Product_Name in the Json.
ALTER TABLE WEBITEMS
ADD Json_PRODUCTNAME AS JSON_VALUE ( ATTRIBUTES , '$.Product_Name' )
CREATE INDEX IX_JSON_PRODUCTNAME
ON WEBITEMS ( Json_PRODUCTNAME )
ALTER TABLE WEBITEMS
ADD Json_PRODUCTNAME AS JSON_VALUE ( ATTRIBUTES , ‘$.Product_Name’ )
Then we add an index to this field.
Now let’s look at our query performance. As you can see, this time it found the correct index and the number of reads dropped from 46781 to 771. A performance increase of approximately 60 times.
Here we can also use the calculated field we added as is.
Conclusion:
In this article, we learned how to query Json data when it is kept as NVARCHAR(max) in SQL Server and how to index Json data.
In this article, you will learn the concept of Vector Search, which is the SQL Server equivalent of the concept of artificial intelligence, which has entered every aspect of our lives, and how I do the vector search process, which is not yet in SQL Server On Prem systems, with the T-SQL codes I wrote. Since the article is quite long, I wanted to write here what you will learn after reading what is explained here. Based on it, you can decide whether you are interested in it or not.
1.What is the vector search process and the concept of vector?
2.Instead of searching for text in the form of Select * from Items where title_ like ‘Lenovo%laptop%bag%’ that we know in SQL Server
When it is said “I am looking for a Lenovo notebook bag”, how to search like a prompt?
Or how can the same result be brought when “I am looking for a notebook backpack with Lenovo Brand” is written in a Turkish dataset?
3.How to vectorize a text?
4.What is cosine distance? How to calculate the similarity of two vectors?
5.How to quickly perform a vector search on SQL Server?
6. How to use Clustered Columnstore Index and Ordered Clustered Columnstore index for advanced performance?
7.How can we create a vector index, which is a feature that is not available in SQL Server.
Or you can download the database I worked on it here: VectorDB100K_EN
1.Introduction
The process we do when we search in SQL Server is obvious, right?
For example, let’s say “Lenovo Notebook Bag” is the phrase we searched for.
Here’s how we can call it.
SELECT * FROM WEBITEMS WHERE TITLE_ LIKE ‘%LENOVO NOTEBOOK BAG%’
We see that there is no result from this, because there is no product in which these three words are neighboor to each other.
In this case, these three words can be mentioned in separate places, but we can write them as follows with the logic that they should be in the same sentence.
SELECT ID, DESCRIPTION_ FROM WEBITEMS WHERE DESCRIPTION_ LIKE N'%Lenovo%' AND DESCRIPTION_ LIKE N'%Notebook%' AND DESCRIPTION_ LIKE N'%Bag%'
As you can see, here are some records that fit this format.
Another alternative method is to perform this search with the fulltext search search operation.
SELECT ID,DESCRIPTION_EN FROM WEBITEMS WHERE
CONTAINS(DESCRIPTION_EN,N'Lenovo')
AND CONTAINS(DESCRIPTION_EN,N'Notebook')
AND CONTAINS(DESCRIPTION_EN,N'Bag')
Of course, the fulltext search process is a structure that works very, very fast compared to others.
Now we have gone over our existing knowledge so far.
2.Vector search operation and vector concept
Now I’m going to introduce you to a new concept. “Vector Search”
Especially after concepts such as GPTs, language models, artificial intelligence came out, the rules of the game changed considerably. We now do a lot of our work by writing prompts. Because artificial intelligence is smart enough to understand what we want with the prompt.
So what’s going on on the SQL Server side at this point?
There are also the concepts of Vector Store and Vector Search.
Basically, here’s the thing.
It converts a text expression into a vector array of a certain length (I used it here with 1536 elements) and keeps the data that way.
The vector here consists of 1536 floats.
We convert all the lines of a column that we keep as text in the table to vector and store them as vectors inside, and when we want to search, we convert the text expression we want to search into vectors and calculate the similarity between these two vectors for all rows and try to find the closest one.
For example, let’s say the sentence we want to search for.
“I am looking for a Lenovo or Samsonite notebook bag.”
When we convert this to vector, we get the following result.
DECLARE @STR AS NVARCHAR(MAX);
SET @STR = 'I am looking for a Lenovo or Samsonite notebook bag.'
DECLARE @VECTOR AS NVARCHAR(MAX);
EXEC GENERATE_EMBEDDINGS @STR, @VECTOR OUTPUT;
SELECT @VECTOR AS VECTOR1536;
“I am looking for a Lenovo or Samsonite notebook bag.”
The procedure called GENERATE_EMBEDDINGSdoes the conversion to vector.
This procedure is not a procedure in SQL Server. AzureSQL has this feature, but not on-prem.
Here, it connects to the Azure OpenAI service and performs the conversion to vector.
Now let’s look at how we make a comparison between two vectors.
Here we use a formula called cosine distance.
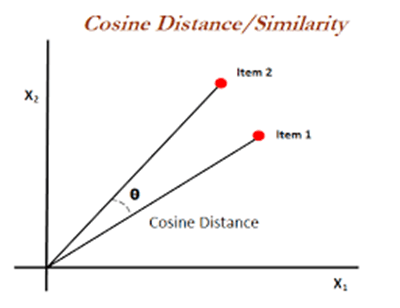
3.Vector Similarity Comparison Cosine Distance
Cosine distance is a distance metric used to measure similarity between two vectors. It is based on the angle between two vectors.
When vectors are facing the same direction, they are considered similar, as they look in different directions, the distance between them increases.
Simply put:
Cosine distance calculates the cosine of the angle between two vectors and gives the degree of similarity.
The larger the cosine of the angle (close to 1), the more similar the two vectors are.
As the cosine distance value approaches 0, the vectors are similar to each other, and as they approach 1, they are different.
It is used to measure content similarity, especially in large data sets such as text and documents.
Of course, since the concept we call vector here is a series with 768 elements, we are talking about a subject that includes all the elements of the vector.
As can be seen in the picture below
Which is a search phrase
‘I am looking for a Lenovo or Samsonite notebook bag.’
With the record in the database
“Lenovo ThinkPad Essential Plus 15.6 Eco Backpack Lenovo 4X41A30364 15.6 Notebook Backpack OverviewThe perfect blend of professionalism and athleticism, the ThinkPad Essential Plus 15.6 Backpack (Eco) can take you from the office to the gym and back with ease. Spacious compartments keep your devices and essentials safe, organized, and accessible, while ballistic nylon and durable hardware protect against the elements and everyday wear and tear. Dedicated, separate laptop compartmentProtect your belongings with the hidden security pocket and luggage strap. Stay hydrated with two expandable side water bottle pockets. Laptop Size Range: 15 – 16 inches, Volume (L): 15, Bag Type: Backpack, Screen Size (inch): 15.6, Color: Black, Warranty Period (Months): 24, International Sales: None, Stock Code: HBCV00000VIMV8 Number of Reviews: 18Reviews Brand: Lenovo Seller: JetKlik Seller Rating: 9.6”
You see the vectors of the sentence translated into vectors and the similarity between them.
Being able to search for similarities from the database through vectors allows us to use the database like a chatbot.
In this case, we can perform a search operation like writing a prompt. There is already such a command in Azure SQL.
It calculates the cosine distance between two vectors and the similarity accordingly.
You can access the article on the subject from the link below.
Here, we’ll try to perform a situation that already exists on Azure SQL on On Prem SQL Server.
First of all, let’s look at how to convert to vector.
We have a table like below.
In this table, the DESCRIPTION_ field is a non-structured text field that contains all the properties of the product. Since we are going to search on this field, we must convert this field to vector.
Since there is no code that converts directly to vector on SQL Server for now, we will do this with an external plugin here. There are a variety of language models here. For example, we can use the Azure Open AI service.
I wrote a procedure like this.
CREATE PROCEDURE [dbo].[GENERATE_EMBEDDINGS]
@INPUT_TEXT NVARCHAR(MAX) = N'I am looking for a Lenovo or Samsonite brand notebook bag',
@VECTORSTR NVARCHAR(MAX) OUTPUT
AS
set @input_text=replace(@input_text,'"','\"')
DECLARE @Object AS INT;
DECLARE @ResponseText AS NVARCHAR(MAX)
DECLARE @StatusText AS nVARCHAR(800);
DECLARE @URL AS NVARCHAR(MAX);
DECLARE @Body AS NVARCHAR(MAX);
DECLARE @ApiKey AS VARCHAR(800);
DECLARE @Status AS INT;
DECLARE @hr INT;
DECLARE @ErrorSource AS VARCHAR(max);
DECLARE @ErrorDescription AS VARCHAR(max);
DECLARE @Headers nVARCHAR(MAX);
DECLARE @Payload nVARCHAR(MAX);
DECLARE @ContentType nVARCHAR(max);
--SET NOCOUNT on
SET @URL = 'https://omeropenaiservice.openai.azure.com/openai/deployments/text-embedding-ada-002/embeddings?api-version=2023-05-15';
SET @Headers = 'api-key: 584eXXXXXXXXXXXXXXXXXXXXXXX';
--Payload to send
SET @Payload = '{"input": "' + @input_text + '"}';
SET @ApiKey = 'api-key: 584eXXXXXXXXXXXXXXXXXXXXXX'
--SET @URL = 'https://api.openai.com/v1/embeddings';
SET @Body = '{"input": "' + @input_text + '"}'-- '{"input": "' + @input_text + '"}';--'{"model": "text-embedding-ada-002", "input": "' + REPLACE(@input_text, '"', '\"') + '"}';
print @body
-- Create OLE Automation object
EXEC @hr = sp_OACreate 'MSXML2.ServerXMLHTTP', @Object OUT;
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to create OLE object';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
RETURN;
END
-- Open connection
EXEC @hr = sp_OAMethod @Object, 'open', NULL, 'POST', @URL, 'false';
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to open connection';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
EXEC sp_OADestroy @Object;
RETURN;
END
-- Set request headers
EXEC @hr = sp_OAMethod @Object, 'setRequestHeader', NULL, 'Content-Type', 'application/json';
EXEC @hr = sp_OAMethod @Object, 'setRequestHeader', NULL, 'api-key', '584XXXXXXXXXXXXXXXXXXXXX';
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to set Content-Type header';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
EXEC sp_OADestroy @Object;
RETURN;
END
EXEC @hr = sp_OAMethod @Object, 'setRequestHeader', NULL, 'Authorization', @ApiKey;
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to set Authorization header';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
EXEC sp_OADestroy @Object;
RETURN;
END
-- Send request
EXEC @hr = sp_OAMethod @Object, 'send', NULL, @Body;
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to send request';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
EXEC sp_OADestroy @Object;
RETURN;
END
-- Get HTTP status
EXEC @hr = sp_OAMethod @Object, 'status', @Status OUT;
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to get HTTP status';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
EXEC sp_OADestroy @Object;
RETURN;
END
-- Get status text
EXEC @hr = sp_OAMethod @Object, 'statusText', @StatusText OUT;
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to get HTTP status text';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
EXEC sp_OADestroy @Object;
RETURN;
END
-- Print status and status text
PRINT 'HTTP Status: ' + CAST(@Status AS NVARCHAR);
PRINT 'HTTP Status Text: ' + @StatusText;
IF @Status <> 200
BEGIN
PRINT 'HTTP request failed with status code ' + CAST(@Status AS NVARCHAR);
EXEC sp_OADestroy @Object;
RETURN;
END
-- Get response text
DECLARE @json TABLE (Result NVARCHAR(MAX))
INSERT @json(Result)
EXEC dbo.sp_OAGetProperty @Object, 'responseText'
SELECT @ResponseText = Result FROM @json
-- Print response text
--SELECT @ResponseText;
-- Destroy OLE Automation object
DECLARE @t AS TABLE (EmbeddingValue nVARCHAR(MAX))
-- Splitting embedded array
SET @vectorstr = (
SELECT EmbeddingValue + ','
FROM (
SELECT value AS EmbeddingValue
FROM OPENJSON(@ResponseText, '$.data[0].embedding')
) t
FOR XML PATH('')
)
SET @vectorstr = SUBSTRING(@vectorstr, 1, LEN(@vectorstr) - 1)
Here is how it’s used.
The vector uses the “text-embedding-ada-002” model and creates a vector with 1536 elements.
Alternatively, we can write a code ourselves in Python without using Azure and we can do vector transformation through another model.
from flask import Flask, request, jsonify
import openai
app = Flask(__name__)
# Azure OpenAI API connection details
openai.api_type = "azure"
openai.api_key = "8nnCxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
openai.api_base = "https://omeropenaiservice.openai.azure.com/"
openai.api_version = "2024-08-01-preview"
# Embedding model and maximum token limit
EMBEDDING_MODEL = "text-embedding-ada-002"
MAX_TOKENS = 8000
app.config['MAX_CONTENT_LENGTH'] = 16 * 1024 * 1024
# Function to generate embeddings using Azure OpenAI API
def get_embedding(text):
embeddings = []
tokens = text.split() # Split the text into tokens using whitespace
# Split the text into chunks and process each chunk
for i in range(0, len(tokens), MAX_TOKENS):
chunk = ' '.join(tokens[i:i + MAX_TOKENS])
response = openai.Embedding.create(
engine=EMBEDDING_MODEL, # Use 'engine' instead of 'model' in Azure OpenAI
input=chunk
)
embedding = response['data'][0]['embedding']
embeddings.append(embedding)
print(f"Chunk {i // MAX_TOKENS + 1} processed") # Log progress
return embeddings
# API endpoint for vectorization
@app.route('/vectorize', methods=['POST'])
def vectorize():
data = request.json
text = data.get('text', '')
if not text or text.strip() == "":
return jsonify({"error": "Invalid or empty input"}), 400
try:
vector = get_embedding(text)
return jsonify({"vector": vector})
except Exception as e:
return jsonify({"error": str(e)}), 500
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
Alternatively, we can write a code ourselves in Python without using Azure and we can do vector transformation through another model.
This code creates a vector with 1536 elements, which takes a string expression into it and consequently converts the vector according to the “all-mpet-base-v2” model.
from flask import Flask, request, jsonify
from sentence_transformers import SentenceTransformer
# Initialize Flask app and model
app = Flask(__name__)
model = SentenceTransformer('all-mpnet-base-v2')
# Define an endpoint that returns a vector
@app.route('/get_vector', methods=['POST'])
def get_vector():
# Retrieve text from JSON request
data = request.get_json()
if 'text' not in data:
return jsonify({"error": "Request must contain 'text' field"}), 400
try:
# Convert the text to a vector
embedding = model.encode(data['text'])
# Convert the embedding vector to a list and return as JSON
return jsonify({"vector": embedding.tolist()})
except Exception as e:
return jsonify({"error": str(e)}), 500
# Run the Flask app
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000)
Now let’s write the TSQL code that will call this API from SQL.
create PROCEDURE [dbo].[GENERATE_EMBEDDINGS_LOCAL]
@str NVARCHAR(MAX),
@vector NVARCHAR(MAX) OUTPUT
AS
BEGIN
DECLARE @Object INT;
DECLARE @ResponseText NVARCHAR(MAX);
DECLARE @StatusCode INT;
DECLARE @URL NVARCHAR(MAX) = 'http://127.0.0.1:5000/get_vector';
DECLARE @HttpRequest NVARCHAR(MAX);
DECLARE @StatusText AS nVARCHAR(800);
DECLARE @Body AS NVARCHAR(MAX);
DECLARE @ApiKey AS VARCHAR(800);
DECLARE @Status AS INT;
DECLARE @hr INT;
DECLARE @ErrorSource AS VARCHAR(max);
DECLARE @ErrorDescription AS VARCHAR(max);
DECLARE @Headers nVARCHAR(MAX);
DECLARE @Payload nVARCHAR(MAX);
DECLARE @ContentType nVARCHAR(max);
SET @Body = '{"text": "' + @str + '"}'
print @body
-- Create OLE Automation object
EXEC @hr = sp_OACreate 'MSXML2.ServerXMLHTTP', @Object OUT;
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to create OLE object';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
RETURN;
END
-- Open connection
EXEC @hr = sp_OAMethod @Object, 'open', NULL, 'POST', @URL, 'false';
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to open connection';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
EXEC sp_OADestroy @Object;
RETURN;
END
-- Set request headers
EXEC @hr = sp_OAMethod @Object, 'setRequestHeader', NULL, 'Content-Type', 'application/json';
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to set Content-Type header';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
EXEC sp_OADestroy @Object;
RETURN;
END
-- Send request
EXEC @hr = sp_OAMethod @Object, 'send', NULL, @Body;
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to send request';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
EXEC sp_OADestroy @Object;
RETURN;
END
-- Get HTTP status
EXEC @hr = sp_OAMethod @Object, 'status', @Status OUT;
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to get HTTP status';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
EXEC sp_OADestroy @Object;
RETURN;
END
-- Get status text
EXEC @hr = sp_OAMethod @Object, 'statusText', @StatusText OUT;
IF @hr <> 0
BEGIN
EXEC sp_OAGetErrorInfo @Object, @ErrorSource OUT, @ErrorDescription OUT;
PRINT 'Failed to get HTTP status text';
PRINT 'Error Source: ' + @ErrorSource;
PRINT 'Error Description: ' + @ErrorDescription;
EXEC sp_OADestroy @Object;
RETURN;
END
-- Print status and status text
PRINT 'HTTP Status: ' + CAST(@Status AS NVARCHAR);
PRINT 'HTTP Status Text: ' + @StatusText;
IF @Status <> 200
BEGIN
PRINT 'HTTP request failed with status code ' + CAST(@Status AS NVARCHAR);
EXEC sp_OADestroy @Object;
RETURN;
END
-- Get response text
DECLARE @json TABLE (Result NVARCHAR(MAX))
INSERT @json(Result)
EXEC dbo.sp_OAGetProperty @Object, 'responseText'
SELECT @ResponseText = Result FROM @json
-- Destroy OLE Automation object
DECLARE @t AS TABLE (EmbeddingValue nVARCHAR(MAX))
SET @vector = (
SELECT EmbeddingValue + ','
FROM (
SELECT value AS EmbeddingValue
FROM OPENJSON(@ResponseText, '$.vector')
) t
FOR XML PATH('')
)
SET @vector = SUBSTRING(@vector , 1, LEN(@vector ) - 1)
End
Here is, how it’s used.
Now let’s convert this to vector for the field we added to the table. I’ll be using the local Azure Open AI service here. The following query converts the field VECTOR_1536 (I used this name because it is a field with 1536 elements) to vector and updates it for all rows in the table.
After a long process, our vector column is now ready and now, we will do a similarity search on this column.
Cosine Distance Calculation Method
import numpy as np
from sklearn.metrics.pairwise import cosine_distances
# Example vectors
A = np.array([1, 2, 3])
B = np.array([4, 5, 6])
# Manual calculation of cosine similarity
cosine_similarity = np.dot(A, B) / (np.linalg.norm(A) * np.linalg.norm(B))
cosine_distance = 1 - cosine_similarity
print("Cosine Distance (manual):", cosine_distance)
# Calculating cosine distance with sklearn
cosine_distance_sklearn = cosine_distances([A], [B])[0][0]
print("Cosine Distance (sklearn):", cosine_distance_sklearn)
Cosine Distance is calculated as follows.
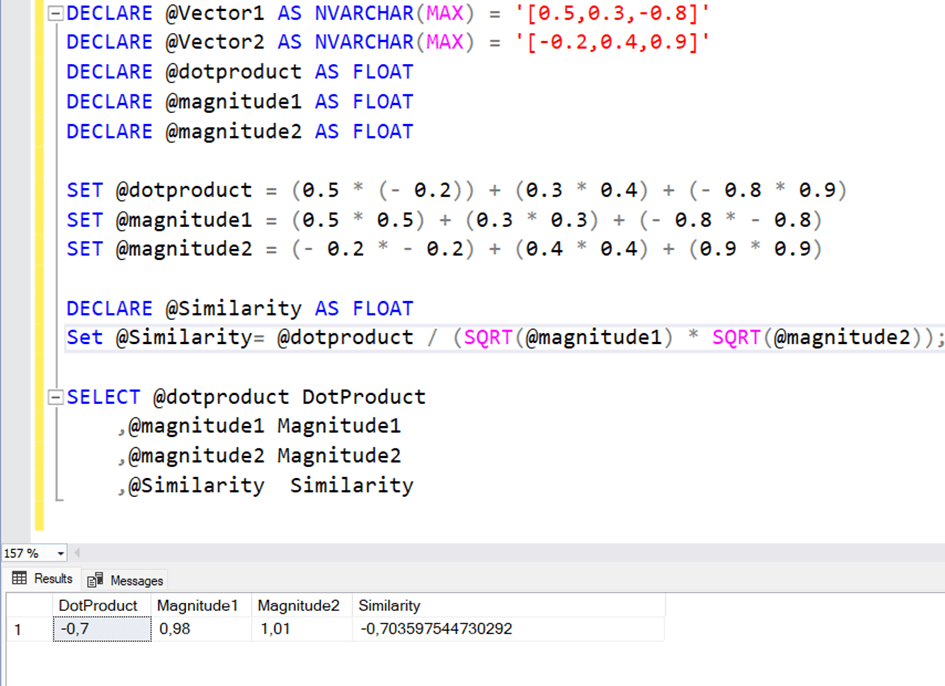
As an example, we have two vectors with 3 elements.
Vector1=[0.5,0.3,-0.8]
Vector2=[-0.2,0.4,0.9]
Here, the cosine distance is calculated as follows.
The sum of each element multiplied by each other is @dotproduct
DECLARE @Vector1 AS NVARCHAR(MAX) = '[0.5,0.3,-0.8]'
DECLARE @Vector2 AS NVARCHAR(MAX) = '[-0.2,0.4,0.9]'
DECLARE @dotproduct AS FLOAT
DECLARE @magnitude1 AS FLOAT
DECLARE @magnitude2 AS FLOAT
SET @dotproduct = (0.5 * (-0.2)) + (0.3 * 0.4) + (-0.8 * 0.9)
SET @magnitude1 = (0.5 * 0.5) + (0.3 * 0.3) + (-0.8 * -0.8)
SET @magnitude2 = (-0.2 * -0.2) + (0.4 * 0.4) + (0.9 * 0.9)
DECLARE @Similarity AS FLOAT
SET @Similarity = @dotproduct / (SQRT(@magnitude1) * SQRT(@magnitude2))
SELECT @dotproduct DotProduct
,@magnitude1 Magnitude1
,@magnitude2 Magnitude2
,@Similarity Similarity
Cosine Distance Calculation Example with TSQL
CREATE FUNCTION [dbo].[CosineSimilarity] (
@Vector1 NVARCHAR(MAX), @Vector2 NVARCHAR(MAX)
)
RETURNS FLOAT
AS
BEGIN
SET @Vector1 = REPLACE(@Vector1, '[', '')
SET @Vector1 = REPLACE(@Vector1, ']', '')
SET @Vector2 = REPLACE(@Vector2, '[', '')
SET @Vector2 = REPLACE(@Vector2, ']', '')
DECLARE @dot_product FLOAT = 0, @magnitude1 FLOAT = 0, @magnitude2 FLOAT = 0;
DECLARE @val1 FLOAT, @val2 FLOAT;
DECLARE @i INT = 0;
DECLARE @v1 NVARCHAR(MAX), @v2 NVARCHAR(MAX);
DECLARE @len INT;
-- Split vectors and insert into tables
DECLARE @tvector1 TABLE (ID INT, Value FLOAT);
DECLARE @tvector2 TABLE (ID INT, Value FLOAT);
INSERT INTO @tvector1
SELECT ordinal, CONVERT(FLOAT, value) FROM STRING_SPLIT(@Vector1, ',', 1) ORDER BY 2;
INSERT INTO @tvector2
SELECT ordinal, CONVERT(FLOAT, value) FROM STRING_SPLIT(@Vector2, ',', 1) ORDER BY 2;
SET @len = (SELECT COUNT(*) FROM @tvector1);
-- Return NULL if vectors are of different lengths
IF @len <> (SELECT COUNT(*) FROM @tvector2)
RETURN NULL;
-- Calculate cosine similarity
WHILE @i < @len
BEGIN
SET @i = @i + 1;
SELECT @val1 = Value FROM @tvector1 WHERE ID = @i;
SELECT @val2 = Value FROM @tvector2 WHERE ID = @i;
SET @dot_product = @dot_product + (@val1 * @val2);
SET @magnitude1 = @magnitude1 + (@val1 * @val1);
SET @magnitude2 = @magnitude2 + (@val2 * @val2);
END
-- Return 0 if any magnitude is zero to avoid division by zero
IF @magnitude1 = 0 OR @magnitude2 = 0
RETURN 0;
RETURN @dot_product / (SQRT(@magnitude1) * SQRT(@magnitude2));
END
Now let’s compare a vector in db with a string expression.
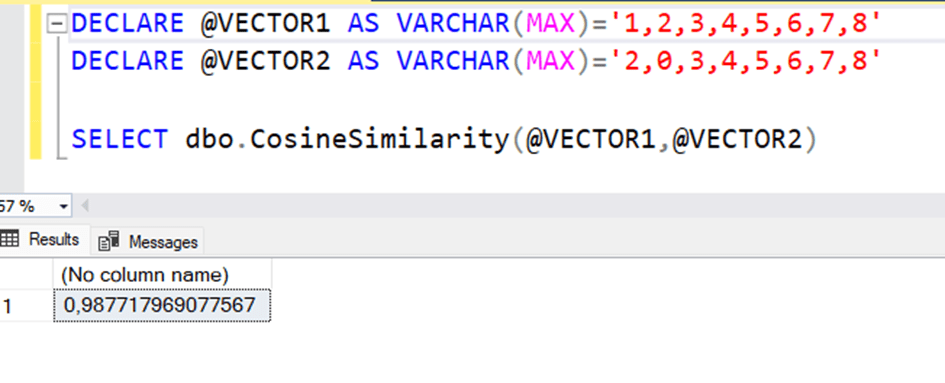
-- Creating a search sentence and converting it to a vector
DECLARE @VECTOR1 AS VARCHAR(MAX) = '1,2,3,4,5,6,7,8';
DECLARE @VECTOR2 AS VARCHAR(MAX) = '2,0,3,4,5,6,7,8';
SELECT dbo.CosineSimilarity(@VECTOR1, @VECTOR2);
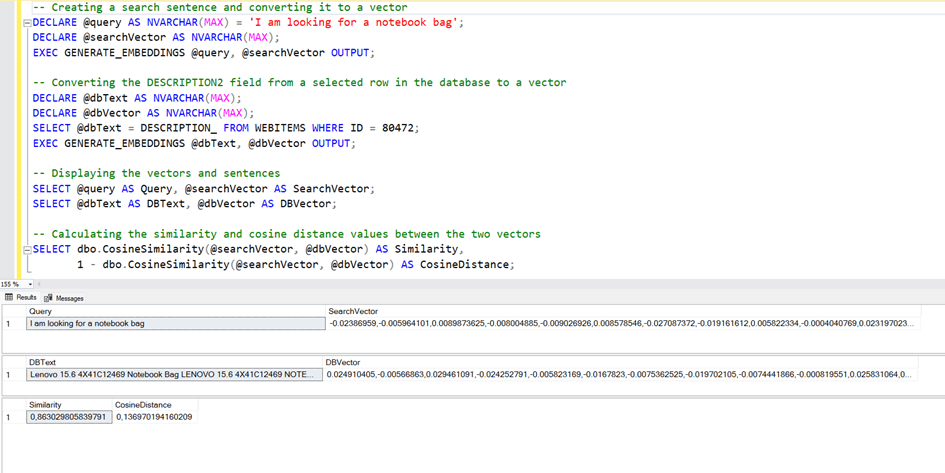
-- Creating a search sentence and converting it to a vector
DECLARE @query AS NVARCHAR(MAX) = 'I am looking for a notebook bag';
DECLARE @searchVector AS NVARCHAR(MAX);
EXEC GENERATE_EMBEDDINGS @query, @searchVector OUTPUT;
-- Converting the DESCRIPTION2 field from a selected row in the database to a vector
DECLARE @dbText AS NVARCHAR(MAX);
DECLARE @dbVector AS NVARCHAR(MAX);
SELECT @dbText = DESCRIPTION_ FROM WEBITEMS WHERE ID = 80472;
EXEC GENERATE_EMBEDDINGS @dbText, @dbVector OUTPUT;
-- Displaying the vectors and sentences
SELECT @query AS Query, @searchVector AS SearchVector;
SELECT @dbText AS DBText, @dbVector AS DBVector;
-- Calculating the similarity and cosine distance values between the two vectors
SELECT dbo.CosineSimilarity(@searchVector, @dbVector) AS Similarity,
1 - dbo.CosineSimilarity(@searchVector, @dbVector) AS CosineDistance;
As can be seen, the similarity of these two text expressions with each other was 0.63. Here we have calculated the similarity with only one record at the moment. However, what should happen is that this similarity is calculated among all the records in the database and a certain number of records come according to the one with the most similarity rate.
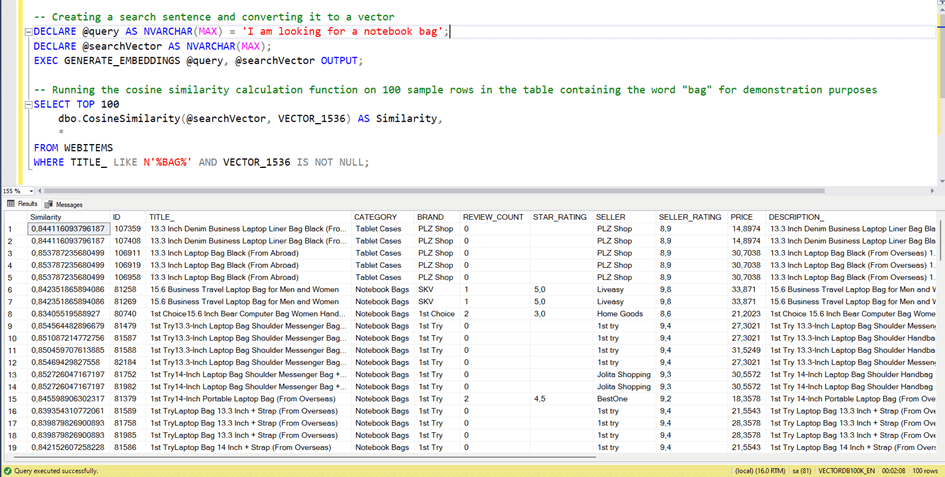
Since there are more than 75.000 records in the database, this function needs to run more than 75.000 times. This is a serious performance issue. Let’s run it for 100 rows of records.
As you can see, even for 100 rows of data, it took 2 minutes. This means approximately 2×1000 = 2.000 minutes for 100 thousand lines, which is about 33 hours.
It’s not abnormal for this amount of time to be.
Because that’s exactly what we’re doing in the background.
1.@dotProduct, there is a multiplication of elements as many as the number of elements of the vectors (our number is 1536) with each other, and then there is the addition of them.
1536 Multiplication+1536 addition=3072 operations
2.There is a process of calculating the sum of the elements by taking the squares of the elements for each vector.
Squaring operation for both vectors 1536 +1536 =3072 operations.
There is a transaction, but it doesn’t matter because it happens 1 time.
In this case, for every vector with 1536 elements, 3072 + 3072 = 6144 operations occur in each line.
In a table of 75.000 rows, this number means 75,000×6144 =460.800.000 (Approximately 460 million) mathematical operations. Therefore, it is possible that it will take so long.
In short, it is not very healthy for us to calculate in this way.
What to do to speed up this work?
Yes, now let’s talk about how to speed up this work.
I’ve said many times that SQL Server likes to work with data in a vertical.
By vertical, I mean the data in the rows and the correct indexes.
But where is the vector data we have? 1536 horizontal data, which is distinguished by a comma next to each other, and sometimes 768 horizontal data according to the language model used.
SQL Server is not good at horizontal data. So how about we convert this horizontal data to vertical?
In other words, if we add each element of the vector to the system as a line.
We will create a table for this.
CREATE TABLE VECTORDETAILS(
id int IDENTITY(1,1) NOT NULL,
vector_id [int] NOT NULL,
value_ float NULL,
key_ int NOT NULL
) ON [PRIMARY]
Here we will keep the ID value for a product as Vector_id here. We will key_ the sequence number of the vector element and keep its value as value_.
As an example, let’s look at the product with ID 80472.
We can read the VECTOR_1536 field line by line with splitting with the comma.
Now let’s write a stored procedure for each product that will update it in the table.
CREATE TABLE [dbo].[VECTORDETAILS](
[id] [int] IDENTITY(1,1) NOT NULL,
[vector_id] [int] NOT NULL,
[value_] [float] NULL,
[key_] [int] NULL
) ON [PRIMARY]
GO
CREATE PROC [dbo].[fillVectorDetailsContentByVectorId_WEBITEMS]
@vectorId as int
CREATE PROCEDURE [dbo].[FILL_VECTORDETAILS_BY_ID]
@VECTOR_ID INT
AS
BEGIN
DELETE FROM VECTORDETAILS WHERE VECTOR_ID = @VECTOR_ID;
INSERT INTO VECTORDETAILS (VECTOR_ID, KEY_, VALUE_)
SELECT
E.ID,
D.ORDINAL,
TRY_CONVERT(FLOAT, D.VALUE)
FROM WEBITEMS E
CROSS APPLY STRING_SPLIT(REPLACE(REPLACE(CONVERT(NVARCHAR(MAX), E.VECTOR_1536), ']', ''), '[', ''), ',',1) D
WHERE E.VECTOR_1536 IS NOT NULL
AND E.ID = @VECTOR_ID;
END;
Now let’s call this procedure for all products.
DECLARE @VECTORID AS INT;
DECLARE CRS CURSOR
FOR
SELECT ID
FROM WEBITEMS;
OPEN CRS;
FETCH NEXT
FROM CRS
INTO @VECTORID;
WHILE @@FETCH_STATUS = 0
BEGIN
EXEC FILL_VECTORDETAILS_BY_ID @VECTORID;
FETCH NEXT
FROM CRS
INTO @VECTORID;
END;
CLOSE CRS;
DEALLOCATE CRS;
Cosine Simularity Fast Calculation
Yes, now that we have come this far, the next step is to quickly calculate similarity. There’s a TSQL code I wrote for this.
— Declare variables
DECLARE @input_text NVARCHAR(MAX) =’I am looking for a Lenovo or Samsonite brand notebook bag’;
DECLARE @vectorstr NVARCHAR(MAX);
DECLARE @vector NVARCHAR(MAX);
— Remove special characters from the input text
SET @input_text = dbo.RemoveSpecialChars(@input_text);
— Create a temporary table to store the vector values
CREATE TABLE #t (
vector_id INT,
key_ INT,
value_ FLOAT
);
— Insert vector values into the temporary table
INSERT INTO #t (vector_id, key_, value_)
SELECT
-1 AS vector_id, — Use -1 as the vector ID for the input text
d.ordinal AS key_, — The position of the value in the vector
CONVERT(FLOAT, d.value) AS value_ — The value of the vector
FROM
STRING_SPLIT(@vectorstr, ‘,’, 1) AS d
— Calculate the cosine similarity between the input vector and stored vectors
SELECT TOP 100
vector_id,
SUM(dot_product) / SUM(SQRT(magnitude1) * SQRT(magnitude2)) AS Similarity,
@input_text AS SearchedQuery, — Include the input query for reference
(
SELECT TOP 1 DESCRIPTION_
FROM WEBITEMS
WHERE ID = TT.vector_id
) AS SimilarTitle — Fetch the most similar title from the walmart_product_details table
into #t1
FROM
(
SELECT
T.vector_id,
SUM(VD.value_ * T.value_) AS dot_product, — Dot product of input and stored vectors
SUM(VD.value_*VD.value_) AS magnitude1, — Magnitude of the input vector
SUM(T.value_*T.value_) AS magnitude2 — Magnitude of the stored vector
FROM
#t VD — Input vector data
CROSS APPLY
(
— Retrieve stored vectors where the key matches the input vector key
SELECT *
FROM VECTORDETAILS vd2
WHERE key_ = VD.key_
) T
GROUP BY T.vector_id — Group by vector ID to calculate the similarity for each stored vector
) TT
GROUP BY vector_id — Group the final similarity results by vector ID
ORDER BY 2 DESC; — Order by similarity in descending order (most similar first)
select DISTINCT vector_id,ROUND(similarity,5) Similarity,similarTitle ProductName from #t1
WHERE similarTitle IS NOT NULL
ORDER BY 2 DESC
DROP TABLE #t,#t1 ;
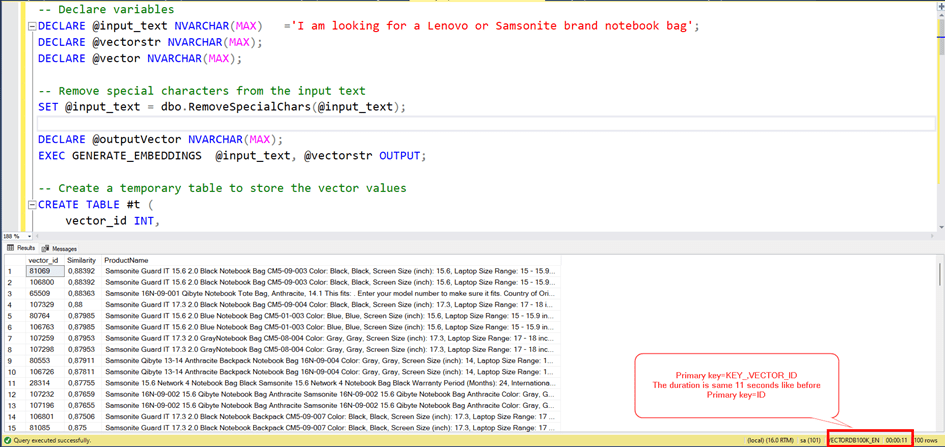
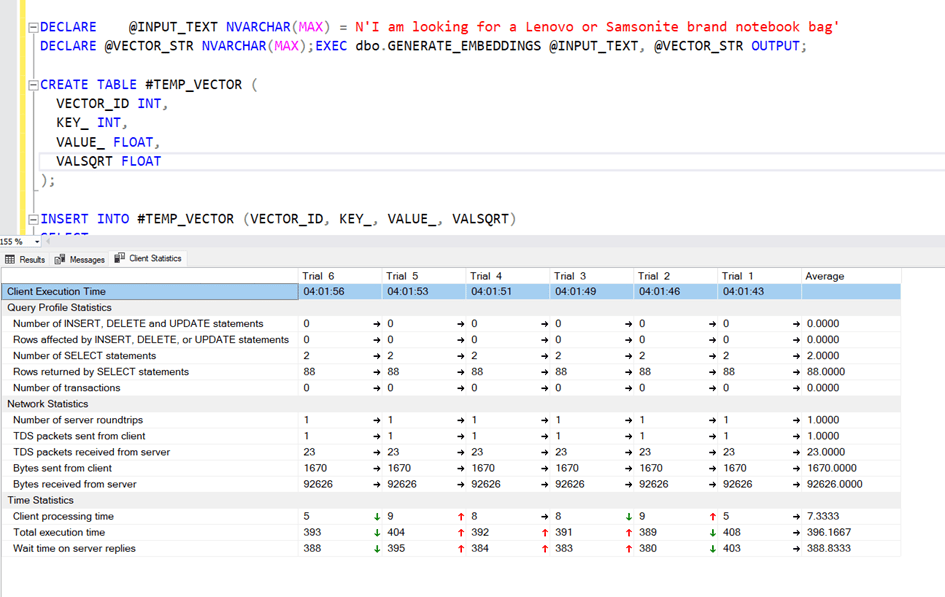
The query seems to be working fine, but the duration is 11 seconds. Actually this is very great time. Because, remember! The first calculation time for the cosinus distance was about 33 hours with table scan.
But I think it can be better.
Let’s work!
We don’t have any nonclustered index for now and we have just primary key for ID column and we have a clustered index for this auto Increment integer field. But our query Works on VECTOR_ID and KEY_ columns.
Let’s try to make these columns primary key.
ALTER TABLE VECTORDETAILS ADD PRIMARY KEY (KEY_,VECTOR_ID)
And try again.
Wee see, the result is same before.
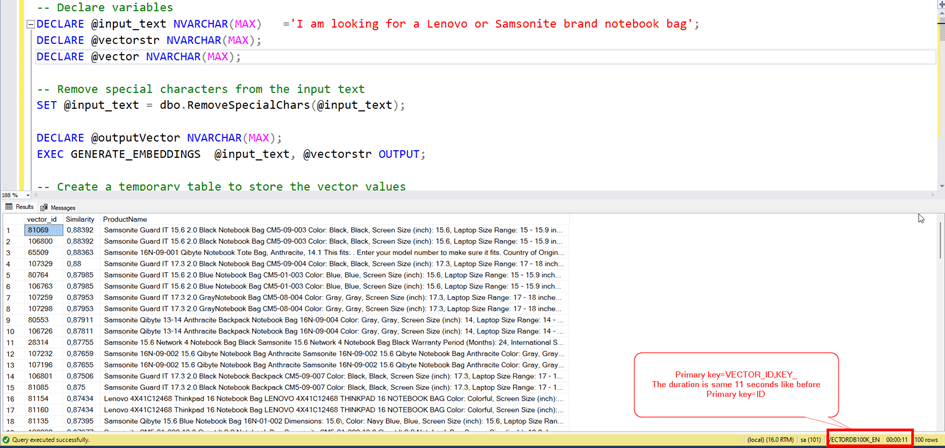
Let’s change the order of primary key columns.
Let’s change the order of primary key columns.
Let’s change the order of primary key columns.
We can try the columnstore index.
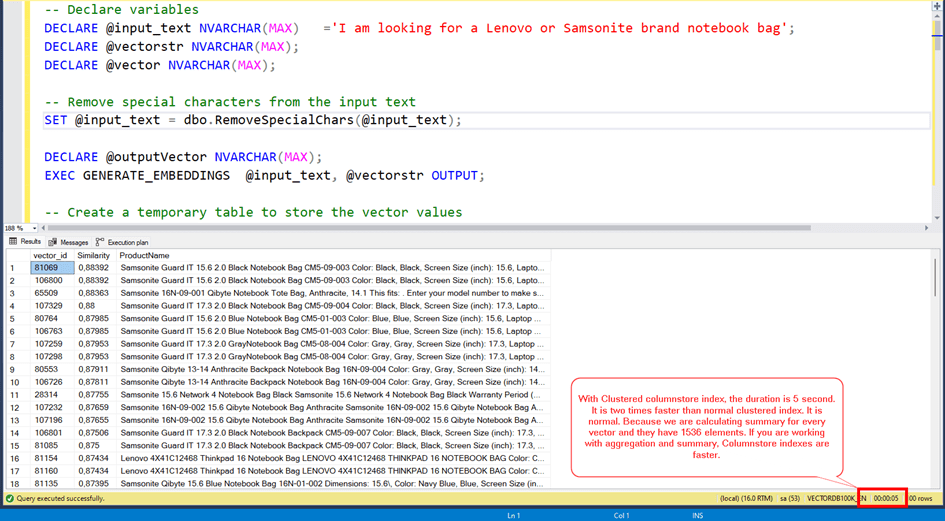
With Clustered columnstore index, the duration is 5 seconds.
It is 2 times faster than normal clustered index. It is normal. Because we are calculating summary for every vector and they have 1536 elements. If you are working with aggregation and summary, Columnstore indexes are faster.
But we also querying data with the KEY_ and VECTOR_ID fields.
We are joining our search vector and the all vectors in our table. (80.000 rows)
We are joining them with the key_ column.
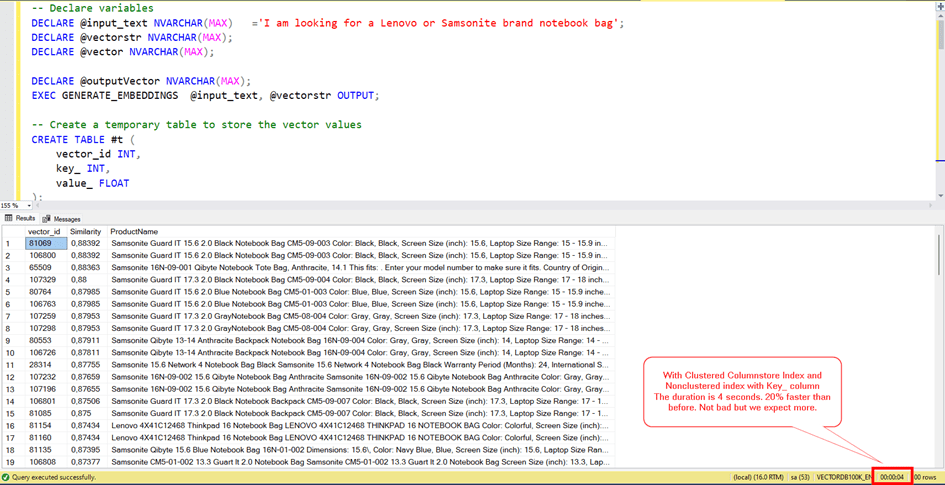
If we use just clustered columnstore index it will be slow. Because CC Indexes are faster for batch reading and aggregating. For row based comprasion, Nonclustered indexes are better.
So we need a non clustered index for the key_ column and also we need included column to decrease to read.
CREATE INDEX IX1 ON VECTORDETAILS(KEY_)
INCLUDE (VECTOR_ID,VALUE_)
With Clustered Columnstore Index and Nonclustered index with Key_ column
The duration is 4 seconds. 20% faster than before. Not bad but we expect more.
Let’s turn back to Cosine similarity formula.
1.DotProduct: In other words, the elements of both vectors in the same order are multiplied by each other.
2.Magnitude1, Magnitude2: The process of summarizing all the elements of both vectors by squaring them and then taking the square root again.
There is no escaping operation for number one. Because it is related to the other vectors in the table.
But for number two, we can decrease reading by calculating it at once and there is no need to calculate it again.
We should add another field to our table and update it.
Alter Table VECTORDETAILS add valsqrt float
Update VECTORDETAILS set valsqrt=value*value_
Now let's add a separate table to calculate the magnitude values.
CREATE TABLE VECTORSUMMARY (
ID INT IDENTITY(1,1),
VECTOR_ID INT,
MAGNITUDE FLOAT,
MAGNITUDESQRT FLOAT
Alter Table VECTORDETAILS add valsqrt float
Update VECTORDETAILS set valsqrt=value*value_
Now let’s add a separate table to calculate the magnitude values.
CREATE TABLE VECTORSUMMARY (
ID INT IDENTITY(1,1),
VECTOR_ID INT,
MAGNITUDE FLOAT,
MAGNITUDESQRT FLOAT
Now let’s group it from the VECTORDETAILS table and insert it here.
INSERT INTO VECTORSUMMARY
(VECTOR_ID, MAGNITUDE, MAGNITUDESQRT)
select VECTOR_ID,SUM(VALSQRT) ,SQRT( SUM(VALSQRT) )
FROM VECTORDETAILS
WHERE VECTOR_ID=@vectorId
GROUP BY VECTOR_ID
)
Finally, let's create an index.
CREATE NONCLUSTERED INDEX IX1 ON dbo.VECTORSUMMARY
(
VECTOR_ID ASC
)
INCLUDE(ID,MAGNITUDE, MAGNITUDESQRT)
Now let’s modify and run our calculation query accordingly.
DECLARE @input_text nVARCHAR(MAX) = N'I am looking for a Lenovo or Samsonite brand notebook bag';
DECLARE @vectorstr nVARCHAR(MAX);
DECLARE @outputVector NVARCHAR(MAX);
EXEC GENERATE_EMBEDDINGS @input_text, @vectorstr OUTPUT;
CREATE TABLE #t (
vector_id INT
,key_ INT
,value_ FLOAT
,valsqrt FLOAT
,magnitude FLOAT
);
-- Insert vector values into the temporary table
INSERT INTO #t (
vector_id
,key_
,value_
,valsqrt
)
SELECT - 1 AS vector_id
,-- Use -1 as the vector ID for the input text
d.ordinal AS key_
,-- The position of the value in the vector
CONVERT(FLOAT, d.value) AS value_
,-- The value of the vector
CONVERT(FLOAT, d.value) * CONVERT(FLOAT, d.value) AS valsqrt -- Squared value
FROM STRING_SPLIT(@vectorstr, ',', 1) AS d
CREATE INDEX IX1 ON #T (KEY_) INCLUDE (
[vector_id]
,[value_]
,[valsqrt]
)
DECLARE @magnitudesqrt AS FLOAT
SELECT @magnitudesqrt = sqrt(sum(valsqrt))
FROM #T
SELECT top 100 T.vector_id
,dotProduct / (sqrt(@magnitudesqrt) * sqrt(vs.magnitudesqrt) ) CosineSimularity
,1 - (dotProduct / (@magnitudesqrt * vs.magnitudesqrt)) CosineDistance
,(
SELECT TOP 1 DESCRIPTION_
FROM WEBITEMS
WHERE id = t.vector_id
) AS description
FROM (
SELECT v2.vector_id
,sum(v1.value_* v2.value_) dotproduct
FROM #t v1 WITH (NOLOCK)
INNER JOIN VECTORDETAILS v2 WITH (NOLOCK) ON v1.key_ = v2.key_
GROUP BY v2.vector_id
,v1.magnitude
,V2.magnitude
) t
LEFT JOIN VECTORSUMMARY VS ON VS.vector_id = T.vector_id
ORDER BY 2 desc
DROP TABLE #t
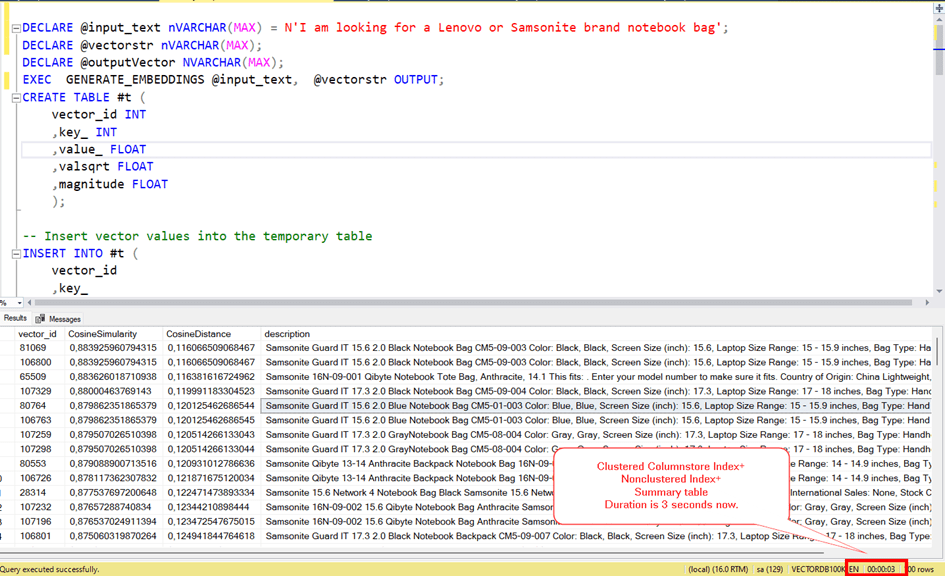
Yes, as you can see now, the search process has decreased to 3 seconds.
And last thing we can try is using Ordered Clustered Columnstore Index.
It is a new feature coming with SQL Server 2022 and it can increase the performance by reducing logical read count.
We should drop current clustered columnstore index. And create ordered version.
DROP INDEX CCIX1 ON VECTORDETAILS
CREATE CLUSTERED COLUMNSTORE INDEX [CCIX1] ON [dbo].[VECTORDETAILS]
ORDER (VECTOR_ID)WITH (COMPRESSION_DELAY = 0, DATA_COMPRESSION = COLUMNSTORE,MAXDOP=1) ON [PRIMARY]
GO
Now, let’s try it with ordered clustered columnstore Index.
Yes! At the end, we did it! It is less than one second.
The vector search process includes a universal search.
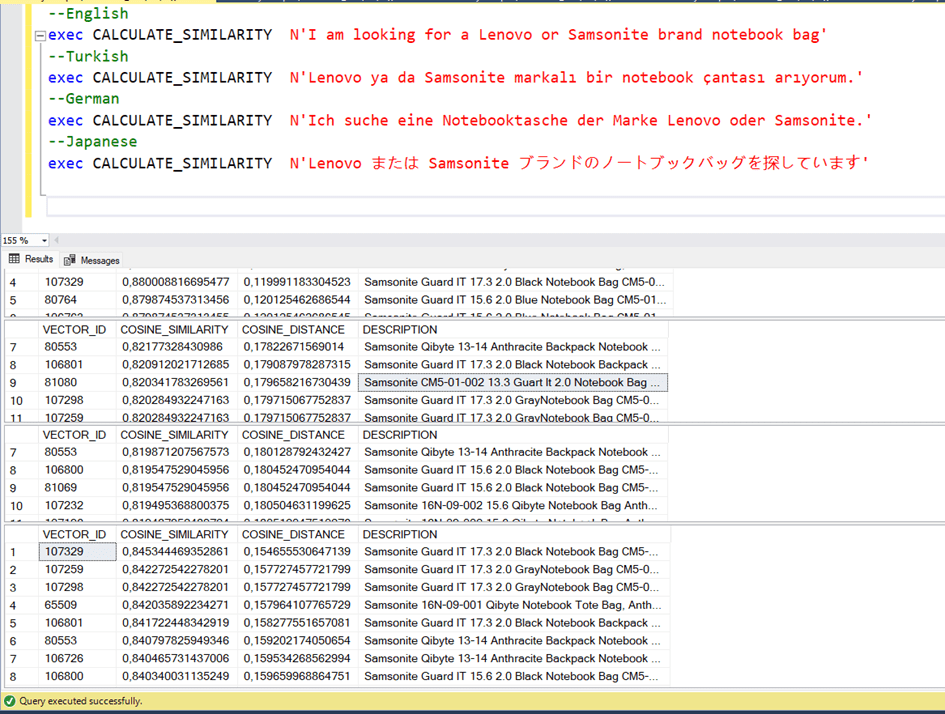
In traditional text-based searches, you make a text-based, word-based comparison as you search. However, in vector search, you search as a semantic integrity. In text-based searches, for example, you cannot perform an English search within a Turkish data set. Or you need to translate the English text before the call.
But vector-based search is a bit like body language universal.
In other words, saying “I’m looking for a laptop bag” and “Bir notebook çantası arıyorum” are very close to each other.
This is how we can try.
Summary and Conclusion
This article walks you through how to perform a vector search operation on On Prem SQL Server 2022.
Currently, since there is no vector search feature on SQL Server 2022, I searched with the algorithm written in TSQL.
In the vector conversion process, the ” “text-embedding-ada-002” model was used and vectors of 1536 elements were created.
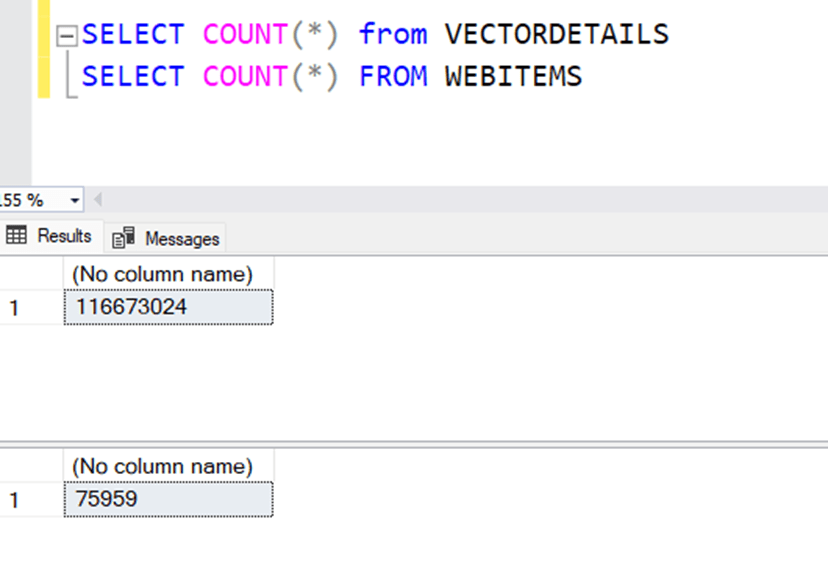
In a table of 75.959 rows, vectors are converted to rows and stored in a table, and the number of rows in this table is 116.673.024 (about 116 million)
The Ordered Clustered Columnstore Index, which comes with SQL Server 2022, was used to perform performance search on this table.
The search performance results are as follows.
-Search with cosine distance function on 75 thousand lines: 33 hours
-Search via primary key by rowing vector elements on 75 thousand lines: 11 sec
-Search on the Clustered Columnstore index by rowing vector elements on 75 thousand lines: 3 sec.
-Search on the Clustered Columnstore index by rowing vector elements on 75 thousand lines: 380 ms.
My Hardware
Device features
Processor:13th Gen Intel(R) Core(TM) i7-13700H 2.40 GHz
Installed RAM:32.0GB
OS: Windows 11 64-bit operating system, x64-based processor
HDD: KINGSTON SNV2S2000G 1.81 TB
Overall Rating
Although vector search is not fully sufficient for search on its own, it brings a very different perspective with its quality as a new search approach and a language-independent semantic integrity search.
When combined with attribute extraction or text search, it will be able to produce very successful results.
In order to further increase system performance, partitioning can be tried on the Clustered Columnstore Index.
I hope you enjoyed it. Hope to see you in another article…
Bu yazıda veri bilimi konusunda sıklıkla yapılan çalışmalardan RFM konusunun SQL Server üzerinde T-SQL kodları yazarak nasıl yapılacağını uygulamalı şekilde anlatacağım.
Konuyu bilmeyenler için RFM Analizi ne demek biraz bahsedelim.
RFM nedir?
Recency, Frequency, Monetary kelimelerinin baş harflerinden oluşup, bu üç metriğin hesaplanmasından sonra birleştirilmesiyle meydana gelen bir skordur. Müşterilerin mevcut durumunun analiz edilip, bu skorlara göre segmentlere ayrılmasına yardımcı olur.
Recency: Müşterinin ne kadardır websitesinden/mağazadan hizmet aldığı, ne zamandır bize üye olduğu gibi bilgileri verir. Hesaplanması genellikle, bugünden son üyelik tarihi/son sipariş tarihinin çıkartılmasıyla elde edilir.
Frequency: Müşterinin ne sıklıkla alışveriş yaptığını, ne sıklıkla siteye giriş yaptığını gösteren metriktir. Genellikle sipariş numarası/sipariş kodunun saydırılmasıyla sonuç verir.
Monetary: Müşterinin harcamalarının toplamıdır. E-ticaret sitesine getirdiği ciro, aldığı hizmetler sonrası toplanan getiri olarak da tanımlanabilir. Ciro tanımı ne ise, müşteri bazında hayatı boyunca yapılan harcamalar toplanarak hesaplanır.
Bu metrikler belirlendikten sonra, metrik bazında müşteri verisi 5 eşit parçaya ayrılır. Sonrasında bu rakamlar bir araya getirilerek bir RFM skoru atanır.
RFM analizi bir satış veriseti üzerinde çalışarak elde edilir ve yapılan çalışma sonucunda bir müşteri sınıflandırma işlemi gerçekleştirilir.
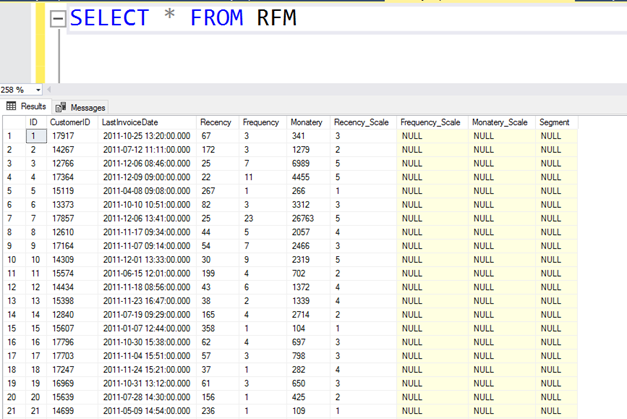
Elde etmek istediğimiz tablo aşağıdaki gibidir.
Burada alanların açıklamaları aşağıdaki gibidir.
CustomerID:Sınıflandırılamak istenen müşterinin ID’sidir. Burada müşteri kodu, müşteri adı gibi bilgiler de olabilir.
LastInvoiceDate:Müşterinin son alışveriş yaptığı tarih ve zaman bilgisini tutar. Bu bilgi bizim Recency değerimizi hesaplamak için kullanacağımız bir alandır.
Recency: Müşterinin en son ne zaman alışveriş yaptığı bilgisinin bir metriğidir. Bugün-Son alışveriş tarihi olarak hesaplanır.
Frequency: Müşterinin ne sıklıkta alışveriş yaptığı bilgisidir. Burada fatura numarası ya da sipariş numarası gibi alanlar distinct olarak sayılarak bulunur.
Monetary: Müşterinin harcamalarının toplamıdır. Yani toplamda bir müşteri parasal olarak ne kadarlık alışveriş yapıyor onun karşılığıdır.
Recency_Scale: Elde edilen Recency değerinin 1-5 arasına sıkıştırılmış halidir. Daha açıklayıcı anlatmak gerekirse, diyelim 100 satır kaydımız var.
100/5=20
Demek ki tüm veriyi Receny değerine göre sıralar isek
Sıralamada
1-20 arası=1
21-40 arası=2
41-60 arası=3
61-80 arası=4
81-100 arası=5 olacak şekilde bir yeniden boyutlandırma (Scale) işlemi yapılmaktadır.
Frequency _Scale: Elde edilen Frequency değerinin 1-5 arasına sıkıştırılmış halidir.
Monetary _Scale: Elde edilen Monetary değerinin 1-5 arasına sıkıştırılmış halidir.
Segment: Elde edilen Recency_Scale, Frequency _Scale, Monetary _Scale değerlerine göre belli bir formül ile müşterinin sınıflandırılmasıdır. Bu sınıflandırmada müşteriler Need_Attention, Cant_Loose,At_Risk,Potential_Loyalists, Loyal_Customers, About_to_Sleep,Hibernating,New_Customers, Promising, Champions
Sınıflarından birine göre sınıflandırılır.
Hadi şimdi işe koyulalım ve RFM analizi için önce veri setimizi indirelim.
Görüldüğü gibi dosyamız bu şekilde bir görünüme sahip.
Dosyada 2009-2010 ve 2010-2011 yılına ait satış verileri bulunmakta. Biz uygulamamızda bu iki veriden birini seçip çalışacağız. İstenirse bu iki veri birleştirilebilir. Biz şimdilik Year 2010-2011 verilerini dikkate alalım.
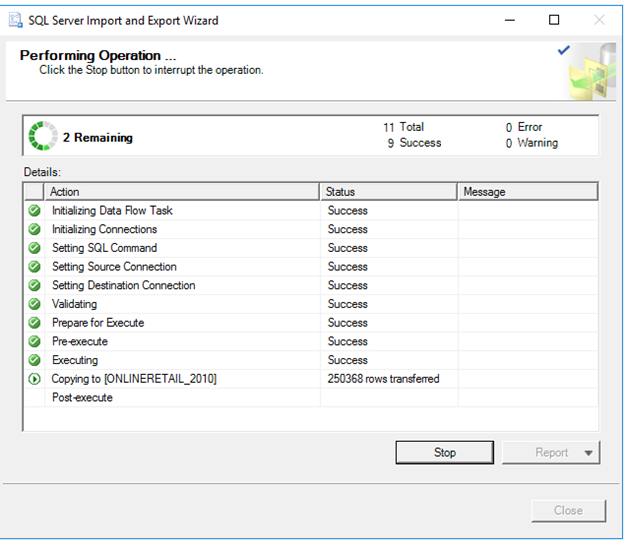
Bu sayfaya baktığımızda 540.457 satırlık bir verinin olduğunu görüyoruz. Tabi burada bir müşteriye ait birden fazla fatura var ve bir faturanın altında da birden fazla ürün satırı var. O yüzden satır sayısı bu kadar fazla.
Şimdi kolonlardan biraz bahsedelim.
Invoice: Fatura numarası
StockCode: Satılan ürünün kodu
Description: Satılan ürünün adı
Quantity: Ürün adedi
InvoiceDate: Fatura tarihi
Price: Ürün birim fiyatı
Customer Id: Müşteri numarası
Country: Müşterinin ülkesi
Şimdi bu excel dosyamızı da gördüğümüze göre artık SQL Server platformuna geçme vakti. Malum yazımızın konusu RFM analizini MSSQL üzerinde gerçekleştirme.
İlk iş bu excel datasını SQL Server’a aktarmak.
Bunun için SQL Server üzerinde RFM isimli bir veritabanı oluşturalım.
Bunun için aşağıdaki gibi New Database diyerek yeni bir database oluşturabiliriz.
RFM isimli database imiz oluştu.
Şimdi bu database e excel dosyasındaki veriyi import edeceğiz. Bunun için database üzerinde sağ tıklayarak Task>Import Data diyoruz.
Next butonuna bastığımızda aşağıdaki hatayı alıyorsanız merak etmeyin çözümü var. Hata almıyorsanız bu kısmı okumasanız da olur.
Bu hatada Microsoft.Ace.Oledb.12.0 provider hatasını görüyoruz. Bu hatayı gidermek için Microsoft Access Database Engine’i bilgisayarınıza yüklemeniz gerekiyor. Bunun için aşağıdaki linki kullanabilirsiniz.
Kurulumu next diyerek default ayarları ile yapabilirsiniz.
Ve kurulum tamamlandı.
Şimdi tekrardan Excel dosyamızı import ediyoruz. Import/Export wizard da kaynak olarak Excel dosyamızı göstermiştik. Hedef olarak ise SQL Server’ı göstereceğiz.
Bağlanacağımız SQL Server’ı seçiyor ve kullanıcı bilgilerini giriyoruz. Benim kullandığım SQL Server kendi makinem olduğu için server name kısmına localhost yazıyor, kullanıcı bilgilerine de Windows authentication’ı işaretliyoruz. Siz de kendi bağlandığınız SQL Server bilgilerini girebilirsiniz.
Copy data from one or more tables or views seçeneğini seçiyoruz.
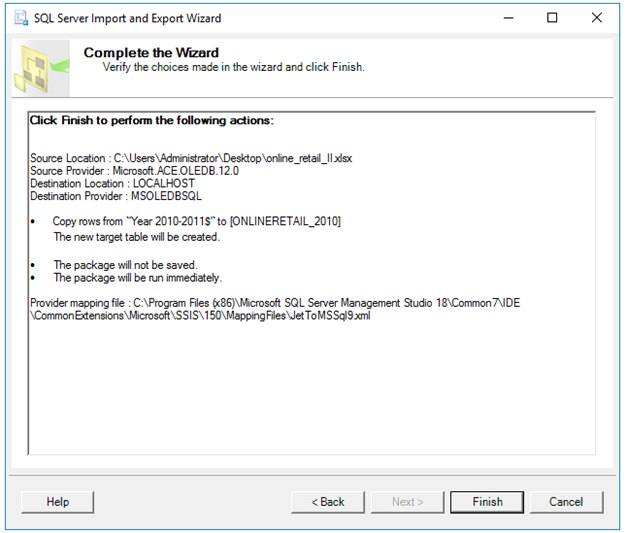
Next dediğimizde karşımıza aşağıdaki ekran geliyor. Source kısmında Excel dosyasındaki sheet adı, Destination kısmında ise SQL Server’da oluşturacağımız tablonun adı geliyor. Burayı elle değiştirebiliyoruz. 2010-211 yılları arasındaki veriyi kullanmayı tercih ediyoruz.
SQL Server’a aktaracağımız tablonun adını ONLINERETAIL_2010 olarak değiştiriyoruz.
Burada Next deyip devam edebiliriz ancak Edit Mappings butonuna basıp yeni oluşan tablonun alanlarını ve veri tiplerini de görebiliriz. Edit Mappings butonuna basında biraz bekleyebilirsiniz. Zira 540.000 satır excel dosyasını okurken ki bekletme bu. Bilgisayar dondu diye panik yapmayın. Biraz beklediğinizde aşağıdaki ekranı göreceksiniz. Tablomuzun alanları ve veri tipleri. OK deyip geçebiliriz.
Next dediğimizde Run Immediately seçeneğini işaretliyoruz ve tekrar Next diyoruz.
Finish diyoruz ve satırlarımızın aktarılmasını bekliyoruz.
Import işlemi tamamlandı.
Şimdi kontrol edelim.
Artık excel dosyamız veritabanımızda. Buraya kadar ki işlemlerde hata yaşadıysanız. Çalıştığımız veritabanını buradaki linkten indirebilirsiniz.
Artık verilerimizi aktardığımıza göre şimdi RFM analizi işlemlerine başlayabiliriz.
Yazımızın ilk başında RFM analizi sonucunda aşağıdaki gibi bir tablo elde etmek istediğimizden bahsetmiştik.
Bu tabloyu elde etmek için yapılan en büyük hatalardan biri karmaşık SQL cümleleri yazarak tek seferde bu tabloyu elde etmeye çalışmak. Şayet SQL bilginiz de çok iyi değilse geçmiş olsun. SQL ile RFM çalışmanız burada son bulacak büyük ihtimalle.
Şimdi daha basit düşünelim. Sonuçta bir excel tablomuz var. Burada tekrar etmeyen CustomerID ler var ve bu CustomerID lere göre hesaplanan bir takım sütunlar var. O zaman aynı bu mantıkta düşünelim ve bu mantıkta bir tablo oluşturup içine önce CustomerId’leri tekrar etmeyecek şekilde dolduralım. Sonra sırayla diğer alanları hesaplayarak gidelim.
İlk iş bu formatta bir SQL tablosu oluşturmak.
Ekteki gibi bir tablo oluşturuyoruz.
Şimdi her seferinde aynı işlemi yapacağımız için önce tablomuzun içini boşaltacak kodumuzu yazalım.
TRUNCATE TABLE RFM
Sonra tablomuzun için tekrar etmeyecek şekilde CustomerID’ler ile dolduralım. Bunun için kullanacağımız komut,
INSERT INTO RFM (CUSTOMERID)
SELECT DISTINCT [Customer ID] FROM ONLINERETAIL_2010
Burada excelden aktarırken Customer ID kolonunda boşluk olduğu için Customer ID yazarken köşeli parantezler içinde yazıyoruz.
4373 kayıt eklendi dedi. Şimdi tablomuzu kontrol edelim.
Şu anda içinde sadece CustomerId olan diğer alanları null olan 4373 satır kaydımız var.
Şimdi sırayla diğer alanları hesaplayalım. İlk hesaplayacağımız alan LastInvoiceDate. Yani müşterinin yaptığı son satınalma zamanının bulunması. Bu değeri bulacağız ki Recency değeri bu tarih ile şimdiki zamanın farkı üzerinden çıkarılacak ve buna göre bulunacak.
Bu işlem için basit bir update cümlesi kullanabiliriz. Aşağıdaki sorgu her bir müşterinin ONLINERETAIL tablosunda son alışveriş yaptığı zamanı bulup update edecektir.
UPDATE RFM SET LastInvoiceDate=(SELECT MAX(InvoiceDate)
FROM ONLINERETAIL_2010 where [Customer ID]=RFM.CustomerID)
Update ettik. Şimdi de sonuca bakalım. Artık LastInvoiceDate alanımız da güncellenmiş durumda.
Bir sonraki adım Recency değerinin bulunması. Bunun için şimdiki zamandan son alışveriş zamanını çıkarmamız ve tablomuzu güncellememiz gerekiyor. Tıpkı bir excel dosyasında satır satır formül çalıştırır gibi sorgu ile satır satır güncelleme yapacağız.
SQL Server’da iki tarih arasındaki farkı alan komut DateDiff komutu. Burada datediff komutu içine üç parametre alır.
1-Farkı ne türünden alacaksın? Gün, Ay, Yıl…
2-Başlangıç zamanı (LastInvoiceDate)
3-Bitiş zamanı (Şimdiki zaman. Fakat bizim veri setimiz 2011 yılında geçtiği için son zamanı 31.12.2011 olarak alabiliriz.
Şimdi update cümlemizi çalıştıralım.
UPDATE RFM SET Recency=DATEDIFF(DAY,LastInvoiceDate,'20111231')
Sonuca bakalım.
Görüldüğü gibi Recency değerini hesaplatmış durumdayız. Sırada Frequency var. Şimdi de onu aşağıdaki sorgu ile bulalım. Frequency bir kişinin ne sıklıkta alışveriş yaptığı bilgisi idi. Yani fatura numaralarını tekil olarak saydırırsak bu değeri bulabiliriz.
UPDATE RFM SET Frequency=(SELECT COUNT(Distinct Invoice) FROM ONLINERETAIL_2010 where CustomerID=RFM.CustomerID)
Şimdi sonuca tekrar bakalım. Görüldüğü gibi Frequency değerimizi de hesapladık.
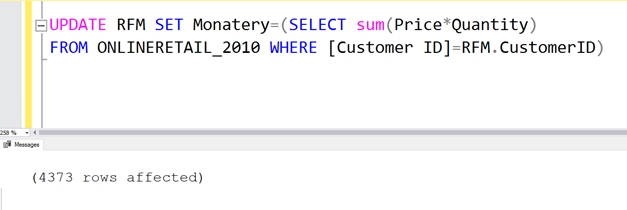
Sırada Monatery değerimiz var. Yani bir müşterinin yapmış olduğu toplam alışverişlerin parasal değeri. Bunu da aşağıdaki sql cümlesi ile bulabiliriz. Burada her bir müşteri için birim fiyat ile miktarı çarptırıyoruz.
UPDATE RFM SET Monatery=(SELECT sum(Price*Quantity) FROM ONLINERETAIL_2010 where CustomerID=RFM.CustomerID)
Sonuçlara bakalım. Görüldüğü gibi Monatery değeri de hesaplanmış oldu.
Artık bu aşamadan sonra R,F ve M değerleri için scale değerlerini hesaplamaya sıra geldi. Bunun için tüm değerleri istenilen kolona göre sıralayıp sıra numarasına göre 1-5 arası değerlendirmeye tabi tutmamız gerekiyor. Bunun için kullanacağımız komut ise Rank komutu.
Kullanımı ise aşağıdaki gibi. Kullanımı karışık gelirse copy-paste yapmanız yeterli.
UPDATE RFM SET Recency_Scale=
(
select RANK from
(
SELECT *,
NTILE(5) OVER(
ORDER BY Recency desc) Rank
FROM RFM
) t where CUSTOMERID=RFM. CUSTOMERID)
Sonuçlara baktığımızda artık Recency_Scale değerini de hesaplamış durumdayız.
Sırada Frequency_Scale var. Onun için de aşağıdaki komutu kullanıyoruz.
update RFM SET Frequency_Scale=
(
select RANK from
(
SELECT *,
NTILE(5) OVER(
ORDER BY Frequency) Rank
FROM rfm
) T where CUSTOMERID=RFM. CUSTOMERID)
Sonuca bakalım. Görüldüğü gibi Frequency_Scale’ da hesaplanmış durumda.
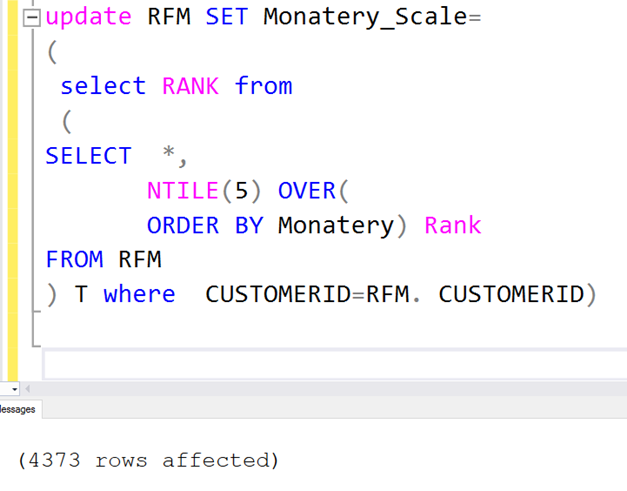
Ve son olarak Monatey_Scale değeri. Onu da aşağıdaki gibi hesaplıyoruz.
update RFM SET Monatery_Scale=
(
select RANK from
(
SELECT *,
NTILE(5) OVER(
ORDER BY Monatery) Rank
FROM rfm
) t where CustomerID=RFM.CustomerID)
Sonuçlara bakalım. Görüldüğü gibi Monatery_Scale’da hesaplandı.
Son olarak artık tüm değişkenlerimiz hesaplandığına göre geriye bir tek sınıflandırma etiketi kaldı. Onun sorgusu hazır durumda. Aşağıdaki sorguya göre sınıflandırmalar yapılabilir.
UPDATE RFM SET Segment ='Hibernating'
WHERE Recency_Scale LIKE '[1-2]%' AND Frequency_Scale LIKE '[1-2]%'
UPDATE RFM SET Segment ='At_Risk'
WHERE Recency_Scale LIKE '[1-2]%' AND Frequency_Scale LIKE '[3-4]%'
UPDATE RFM SET Segment ='Cant_Loose'
WHERE Recency_Scale LIKE '[1-2]%' AND Frequency_Scale LIKE '[5]%'
UPDATE RFM SET Segment ='About_to_Sleep'
WHERE Recency_Scale LIKE '[3]%' AND Frequency_Scale LIKE '[1-2]%'
UPDATE RFM SET Segment ='Need_Attention'
WHERE Recency_Scale LIKE '[3]%' AND Frequency_Scale LIKE '[3]%'
UPDATE RFM SET Segment ='Loyal_Customers'
WHERE Recency_Scale LIKE '[3-4]%' AND Frequency_Scale LIKE '[4-5]%'
UPDATE RFM SET Segment ='Promising'
WHERE Recency_Scale LIKE '[4]%' AND Frequency_Scale LIKE '[1]%'
UPDATE RFM SET Segment ='New_Customers'
WHERE Recency_Scale LIKE '[5]%' AND Frequency_Scale LIKE '[1]%'
UPDATE RFM SET Segment ='Potential_Loyalists'
WHERE Recency_Scale LIKE '[4-5]%' AND Frequency_Scale LIKE '[2-3]%'
UPDATE RFM SET Segment ='Champions'
WHERE Recency_Scale LIKE '[5]%' AND Frequency_Scale LIKE '[4-5]%'
Sonuçlara bakalım.
Artık tüm müşterilerimizi sınıflandırmış durumdayız. Hatta hangi sınıftan kaç müşteri olduğuna da bakalım.
Vee işlem tamam.
Bu yazımızda SQL Server üzerinde sadece TSQL kodları kullanarak RFM Analizi çalışması yaptık. Çalışmada Online Retail datasını kullandık. Aşağıdaki kodu kullanarak OnlineRetail datasını aktardıktan sonraki tüm RFM hesaplama işlemlerini tek seferde yapabilirsiniz.
Buraya kadar sabırla okuduğunuz için çok teşekkür ederim.
İleriye yönelik sistem kaynak planlaması yaparken verilerinizin ne kadar büyüdüğünü görmek önemlidir. Aşağıdaki script sql backupları üzerinden databaselerinizin aylık ne kadar büyüdüğünü göstermektedir. Güzel ve kullanışlı bir script olduğu için paylaşmak istedim. Kaynak:https://www.mssqltips.com/
SELECT DATABASE_NAME,YEAR(backup_start_date) YEAR_ ,MONTH(backup_start_date) MONTH_ ,
MIN(BackupSize) FIRSTSIZE_MB,max(BackupSize) LASTSIZE_MB,max(BackupSize)-MIN(BackupSize) AS GROW_MB,
ROUND((max(BackupSize)-MIN(BackupSize))/CONVERT(FLOAT,MIN(BackupSize))*100,2) AS PERCENT_
FROM
(
SELECT
s.database_name
, s.backup_start_date
, COUNT(*) OVER ( PARTITION BY s.database_name ) AS SampleSize
, CAST( ( s.backup_size / 1024 / 1024 ) AS INT ) AS BackupSize
, CAST( ( LAG(s.backup_size )
OVER ( PARTITION BY s.database_name ORDER BY s.backup_start_date ) / 1024 / 1024 ) AS INT ) AS Previous_Backup_Size
FROM
msdb..backupset s
WHERE
s.type = 'D' --full backup
and s.database_name='<dbname>'
) T GROUP BY DATABASE_NAME,MONTH(backup_start_date),YEAR(backup_start_date)
Bu yazı 2011 yılında yazılmıştır. İlginç bir sorun ve çözüm içerdiği için tekrar paylaşmak istedim.
Geçenlerde bir sistem upgrade’i yaptık. Server ımız değişti, Sistemde database olarak SQL 2005’ten SQL 2008’e, İşletim sistemi olarak Windows Server 2003’ten Windows Server 2008’e geçtik ve cluster yapısı kurduk. ERP Sistemimizde de versiyon geçişi yaptık ve yeni versiyonun çalışması için client bilgisayarlarda mdac versiyon upgrade’ine ihtiyaç duyduk. Sonuç olarak çok ilginç bir sorunla karşılaştık. Kullanıcı tarafındaki çok basit bir işlem kimi bilgisayarda 1 sn sürerken kimi bilgisayarda 20 sn sürüyordu. Sonuç olarak sorun server kaynaklı, İşletim sistemi kaynaklı, SQL 2008 kaynaklı, Erp programı kaynaklı, ya da mdac kaynaklı olabilirdi. Çünkü bunların hepsi de değişmişti. Epey bir inceleme yaptık sorun üzerinde. Öncelikle şunu söyleyim bu ayarla alakalı sql server üzerinde bir article bulamadım. Ancak başka uygulamalarda benzer sıkıntılar yaşanmış onun üzerine bu konu üzerine gittik. Burada yeni ethernetler Jumbo frame denilen yapıyı destekliyor ve normalde 1500 byte lık olan network paketleri 9000 byte olarak tek seferde gönderiyor. Paketleri parçalama işini client ın etherneti yapıyor. Özellikle benzer işlem tekrarlarında bu durumu sistem otomatik olarak yapıyor yani kendince optimize etmeye çalışıyor. Client’ta özellikle döngüye takıp aynı sonucu döndüren tek satırlık ya da çoğunlukla sıfır satırlık select cümlelerinin kullanıldığı yerlerde bu özellik devreye giriyor. Eğer karşıdaki ethernet jumbo paketi desteklemiyor ise paket tekrardan servera gönderiliyor bu kez server bu paketi tekrardan parçalayıp client a gönderiyor. Bu da her paket için yapıldığında yaklaşık 10 kat bazen daha fazla gecikmeye sebep oluyor. Çözüm iki türlü ya serverdan Large Recive Offload Data özelliğini disable etmek ya da client da jumbo paket size değerini arttırmak. Ancak clientta işlem yapmanın iki dezavantajı var bunlardan biri ethernet ya da switchler desteklemiyor olabilir ikincisi de bu özellik enable yapıldığında networkte büyük paketler dolaşmaya başladığından networku tıkayabilir. Bu konuda bir kaç kişiye sorduk pek önermediler büyük paketleri. En doğrusu server üzerinde bu ayarı disable etmek gibi görünüyor. Biz bu ayarı serverda disable ederek sorunu çözdük. Zaten eski serverda ethernet desteklemiyormuş ondan sorun olmamış. Bu bahsettiğim sorundan kaynaklı sıkıntı olduğunu düşündüğün makinada sorun olup olmadığını anlamak için performance monitorden send packet/sec değerlerine bakılabilir. Hızlı makina ile yavaş makina arasındaki fark en az 10 kat oluyor. Aşağıda bu ayarın nasıl yapıldığının resmi mevcut.
“Sql server detected a logical consistency-based i/o error” diye başlayan bir hatayla karşılaşmışsanız geçmiş olsun. Muhtemelen diskte bir sektör okuma hatası var. SQL Server’ın en küçük yapıtaşı olan 8 KB’lık page’lerden bir ya da birkaçı bozulmuş. Koskoca milyon satırlık tabloda sadece 3-5 satır bozuk diye sorgunuz çalışmıyor. Tüm database i yedekten dönseniz yeni eklenen kayıtlar gidecek bu kez. Neyse ki kolay bir yolu var. Database’i page bazlı olarak yedekten dönebilme. Yazdım. Beğenmeniz dileğiyle.
Bu makalemizde SQL Server tarafında yapılan maniplasyonların (Insert, Update, Delete) geri planda otomatik olarak kayıt altına alınmasını anlatıyor olacağız.
Şimdi bir senaryo düşünelim. Bir ticari yazılımımız var. Bu yazılımı dışarıdan satınaldık ve özelliklerine müdahele edemiyoruz kaynağı bizde olmadığı için.
Sistem üzerinde önemli bir fatura hareketinin değiştirildiğini ya da çıkarıldığını düşünelim. Son dönemlerdeki ticari yazılımlar bunların kayıt altına alınmasına izin veriyor ancak vermeyenler de var. Bu anlamda bizim database bazında bu kayıtların loglanmasına ihtiyacımız söz konusu.
Bu işlerle biraz uğraşanlar için ilk akla gelen tabiki trigger yazılması. Doğru bu bir çözümdür ancak sıkıntıları vardır.
Bu sıkıntılar genel olarak şöyledir;
Sizin yazdığınız trigger ticari programın kendisinin hata vermesine sebep olabilir ve kayıtların yapılmamasına sebep olabilir. Zira trigger lar transactionların bir parçasıdır ve trigger da gerçekleşen hata tüm transaction ı rollback yapar.
Özellikle mevzuat değişimi gereği sıklıkla versiyon geçişi söz konusudur ve bu versiyon geçişlerinde database düzenlemesi yapıldığı için büyük ihtimal trigger larınız silinir ve her seferinde yeniden oluşturacak scriptler oluşturmanız gerekecektir.
Genel olarak Türkiye şartlarında dönem mali dönem bağımlı çalışmak tercih edildiği için her yıl başında fiziken yeni tablolar oluşturulmaktadır ve bunlar için de trigger lar yeniden yazılmalıdır.
Anlaşılacağı üzere trigger meselesi etkin bir çözümdür fakat biraz zahmetlidir.
Peki bizim yazımızın da konusu olan bu durum için bir çözüm yok mu? Birim fiyatı 5000 TL olan bir malzemenin satış faturasındaki fiyatını 50 TL olarak değiştiren bir kişiyi tespit etmenin pratik bir yolu yok mudur?
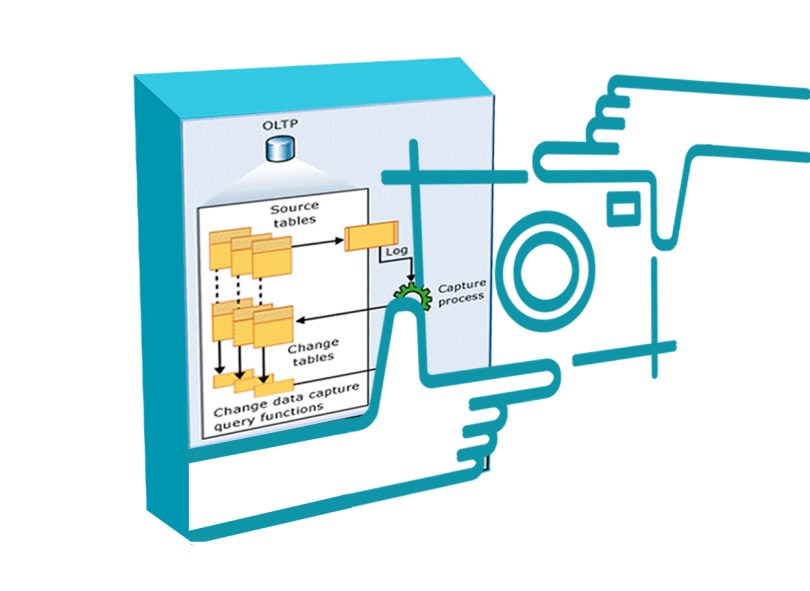
Bu noktada imdadımıza SQL Server Change Data Capture (CDC) dediğimiz özellik yetişiyor. Bu arkadaş yetenekli bir arkadaş. SQL Server’da bildiğiniz üzere tüm manipülasyon işlemleri önce Log dosyasına sonra Data dosyasına yazılır. Burada log dosyası diye bahsettiğim SQL server’ın sistem log dosyası değil database’in Log dosyasıdır (LDF).
İşte CDC sistem üzerinde Log dosyasını izler ve olan değişiklikleri hızlı bir şekilde kayıt altına alır.
Örnek olarak siz aşağıdaki gibi bir UPDATE cümlesi çalıştırdınız.
CUSTOMERS tablosunun 20 alandan oluştuğunu varsayalım oysa biz sadece bir alanı update ettik. Dolayısıyla SQL Server transaction log üzerinde sadece bir alanlık işlem hacmi söz konusu.
İşte Change Data Capture sadece bu bilgiyi okuyarak arka planda veriyi logluyor.
Siz CDC yi configure ederken belli bir süreliğine dataları loglayıp belli bir tarihten öncesini sildirebiliyorsunuz. Burada yazacağınız bir script ile önce bu datalara herhangi bir warehouse ortamına alıp daha sonra sistemden temizleyebilirsiniz.
Öncelikle şunu başta belirtmek isterim ki bu özellik SQL Server 2008 den beri vardır ancak Enterprise edition üzerinde çalışır. Tabi test ortamları için developer edition da enterprise ın tüm özelliklerine sahiptir.
Şimdi bu CDC nasıl çalışıyor bir bakalım.
1. Önce bir tablo oluşturalım.
2.Database imizde CDC yi enable yapıyoruz.
3.Tablomuzda CDC yi enable yapalım.
CDC yi enable ettikten sonra system tables altında aşağıdaki tablolar oluşur.
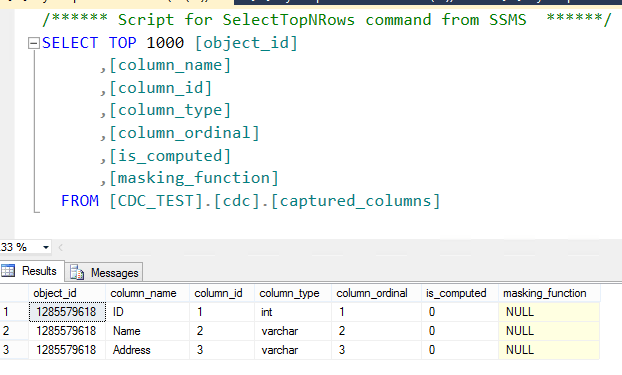
cdc.captured_columns : Adından da anlaşılacağı üzere değişikliklerin takip edileceği kritik alanları tutar. Bu tablo manuel olarak edit edilebilir durumda olup içeriği değiştirilebilir.
cdc.change_tables :Hangi tabloların değişiminin takip edileceği bilgisini tutar.
cdc.lsn_time_mapping: Asıl Tablo üzerinde yapılan her transaction işlemi bu tablo içerisinde tutulur ve içerisindeki lsn bilgisine göre hangi sırada yapıldığı bilgisi tutulur.
4.Şimdi bir kayıt ekleyelim.
5.UPDATE yapalım.
6.DELETE Yapalım
Görüldüğü gibi tablo üzerinde 2 insert,1 update ve 1 delete işlemi yaptık. Burada sistemde 4 satır kaydın logunun tutulması gerekiyor. Bakalım görebilecek miyiz?
Şimdi tablolarımıza bir bakalım.
CDC.captured_colums tablosu
CDC.ddl_history tablosu
CDC.index_column tablosu
CDC.lsn_time_mapping tablosu
Sistemde loglanan kayıtları ya doğrudan ya da tarih parametresi alan table valued function lar ile görebiliyoruz. Bu tablodaki kayıtlar ise log sequence number (lsn) ile tutuluyor. Bu fonksiyonlar da yine tablo bazlı olarak otomatik oluşuyor. Aşağıdaki resimde bu fonksiyonları görebilirsiniz.
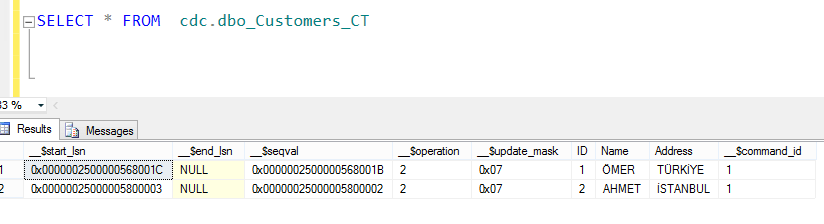
Log kayıtlarını ulaşmak istediğimizde eğer tablonun tamamına ulaşmak istiyor isek
select
* from cdc.dbo_customers_CT şeklinde kullanıyoruz.
burada tablo formatı cdc.<schema>_<tablename>_CT şeklinde.
Bunun kullanımını sonucu aşağıdaki gibi.
table valued functionlar ise aşağıdaki gibi kullanılıyor.
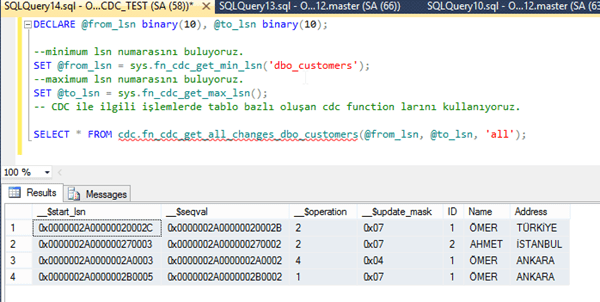
DECLARE @from_lsn binary(10), @to_lsn binary(10);
–minimum lsn numarasını buluyoruz.
SET @from_lsn = sys.fn_cdc_get_min_lsn(‘dbo_customers’);
–maximum lsn numarasını buluyoruz.
SET @to_lsn = sys.fn_cdc_get_max_lsn();
— CDC ile ilgili işlemlerde tablo bazlı oluşan cdc function larını kullanıyoruz.
SELECT * FROM cdc.fn_cdc_get_all_changes_dbo_customers(@from_lsn, @to_lsn, ‘all’);
Görüldüğü üzere sistem 4 adet fazladan alan ve sistemde yapılan değişiklik üzerine loglanan kayıtları getirdi.
Burada
__$start_lsn log: sequence number bilgisini içeriyor. Buradan kayıt tarihine erişebiliyoruz.
__$seqval: Sequnce değeri yani işlemin hangi sırada gerçekleştiği bilgisine erişmek için bu alan kullanılıyorç
__$operation:2 Insert, 4 Update ve 1 Delete için kullanılıyor.
__$operation:1 Insert,Delete 0 Update
anlamına gelmektedir.
Burada kayıt zamanını elde etmek istediğimizde
sys.fn_cdc_map_lsn_to_time function ını kullanıyoruz.
select sys.fn_cdc_map_lsn_to_time(__$start_lsn) as KayitZamani,
* from cdc.dbo_customers_CT
Burada oluşan log kayıtlarını temizlemek için ise
sp_cdc_cleanup_change_table
komutunu kullanıyoruz.
Kullanımı aşağıdaki gibi.
— aşağıdaki kod 3 gün öncesine ait logları temizliyor. declare @lsn binary(10); set @lsn = sys.fn_cdc_map_time_to_lsn(‘largest less than or equal’,getdate()-3); exec sys.sp_cdc_cleanup_change_table @capture_instance = ‘dbo_Customers’, @low_water_mark=@lsn
–CDC yi disable etmek için ise sp_cdc_disable_db, sp_cdc_disable_table komutları kullanlr
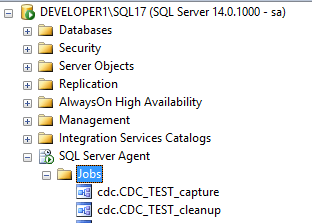
CDC çalıştırabilmek için SQL Server agent a ihtiyacımız söz konusu. Sistem 2 adet job ı otomatik olarak oluşturmaktadır. Bunlardan birisi değişen datanın capture edilmesini sağlarken diğeri de logları temizlemektedir.
Sonuç:
CDC gerçekten çok ihtiyaç duyulan ve çok kullanışlı bir araç.
Sistemdeki insert, update ve delete leri loglayabiliyor.
Eğer update cümlesinde kayıt değişmiyor ise gereksiz yer teşkil etmiyor.
Örneğin: UPDATE CUSTOMERS SET NAME=NAME cümlesini çalıştırdığımızda herhangi bir loglama yapmıyor çünkü değişen bir şey yok.
Sistemin çalışıyor olması için SQL Server Agent’ın mutlaka çalışması gerekir. Çünkü loğları okuyan bir job bu işleri yerine getirmektedir.
Yazacağımız bir script ile istediğimiz tablolarda çalıştırıp istemediklerimizde çalıştırmayabiliriz. Hatta çok fazla kolon olan bir tabloda istediğimiz kolonlar için aktif hale getirirken istemediklerimizi es geçebiliriz.
Bu yazımızda SQL Server’daki bir tabloyu sıkıştırma yani Compress özelliğinden bahsediyor olacağım. Bir çoğumuz veritabanlarında text veriler kullanıyoruz. Bu verilerde ise gerek veritabanı mimarisi sebebiyle ya da gerekse içerisindeki veriler sebebiyle boşluklar bulunmakta. Bu boşluklar ise gereksiz yer teşkil etmekte.
Özellikle varchar, varbinary gibi alanlar yerine char,binary gibi veri tipleri kullanımı veritabanımızın gereksiz büyümesine sebep oluyor. Hazır paket programlarda bu veritabanı mimarisinde değişiklik yapamıyoruz ancak SQL 2008’den bu tarafa olan compress özelliğini kullanabiliriz.
Şimdi elimizde bir tane tablosu olan bir database i miz var. Özellikle tek tablo kullandım ki yaptığımız kazancı rahatlıkla görebilelim.
Tablomuz yaklaşık olarak bu şekilde.
Bu da tablomuzun normalizasyon yapısı. Görüldüğü gibi çok sayıda char tipinde alanlar kullanılmış.
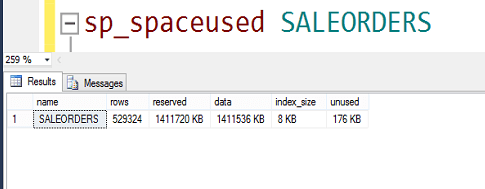
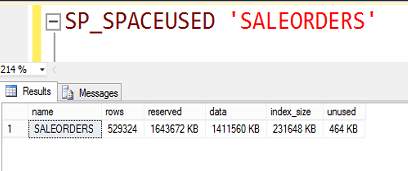
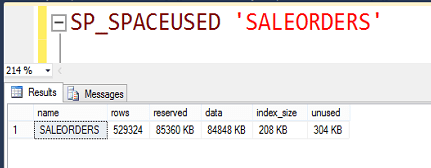
Şimdi bir de tablomuzun diskte kapladığı alana bakalım.
Satır sayısı: 529.324
Kaplanan alan:1,4 GB
Görüldüğü gibi yaklaşık 1.4 GB büyüklüğünde tek tablolu bir database imiz var.
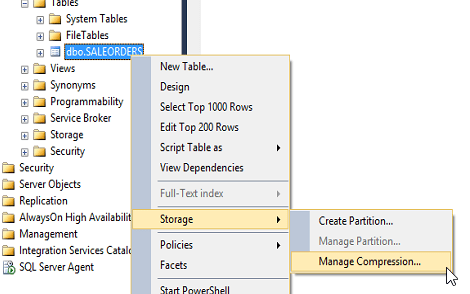
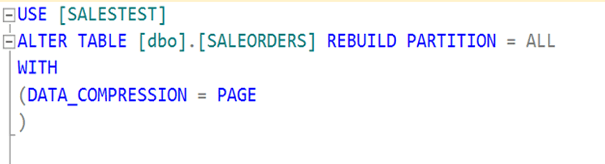
Şimdi bu tabloyu sıkıştırmayı deneyelim.
Tablo üzerinde sağ tık Storage>Manage Compression diyoruz.
Karşımıza bir wizard çıkıyor.
Tablo ile alakalı 3 tür sıkıştırma yapısı var.
None:Sıkıştırma yok
Row:Satır bazlı sıkıştırma
Page:Page bazlı sıkıştırma.
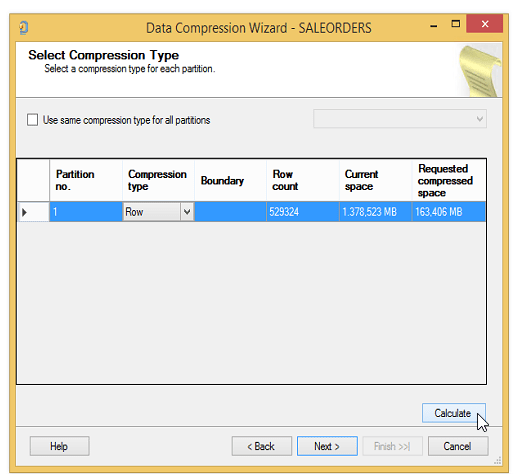
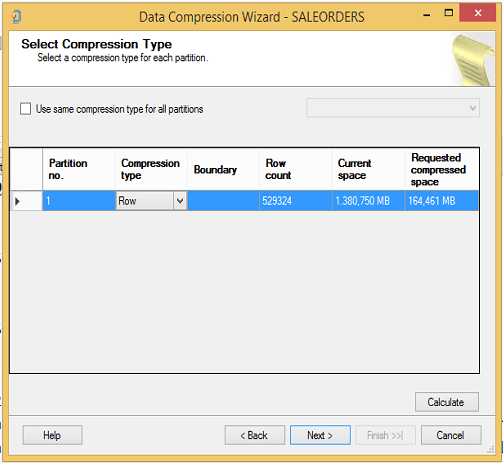
Şimdi Row seçelim ve Calculate tuşuna basalım.
1.378 MB’lık tablonun 163 MB’a düşeceğini öngörüyor. Yani 1378/163=8.5 kat sıkıştırma.
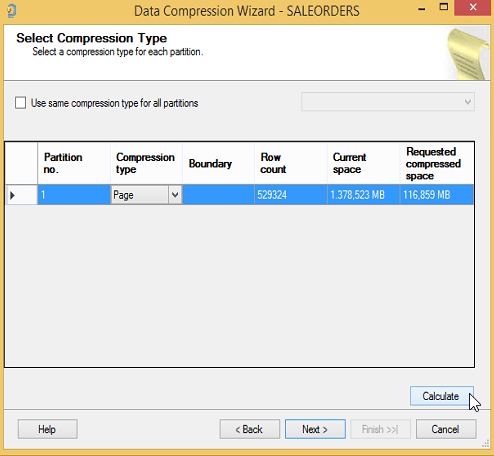
Şimdi de Page seçelim ve Calculate tuşuna basalım.
O da 116 MB çıkardı. Yani Yani 1378/116=11,7 kat sıkıştırma. Burada page ya da row based sıkıştırma daha iyi diye bir yorum yapmak zor. O yüzden calculate yapıp hesaplamak daha mantıklı.
Şimdi akla gelen bir diğer soru ise performans. Yani sıkıştırılmış bir tabloda sorgu performansı ne olur.
Gelin onu da hep birlikte deneyelim.
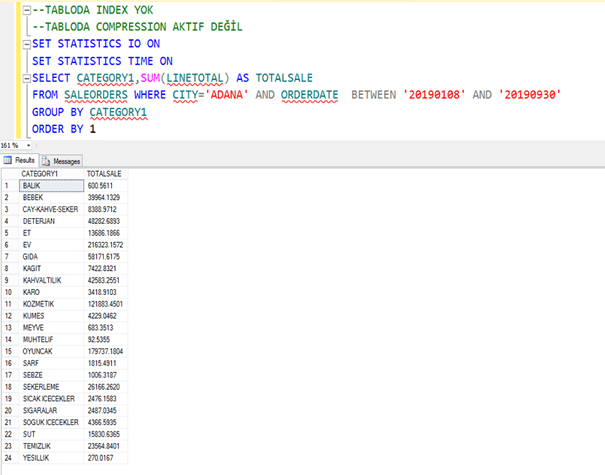
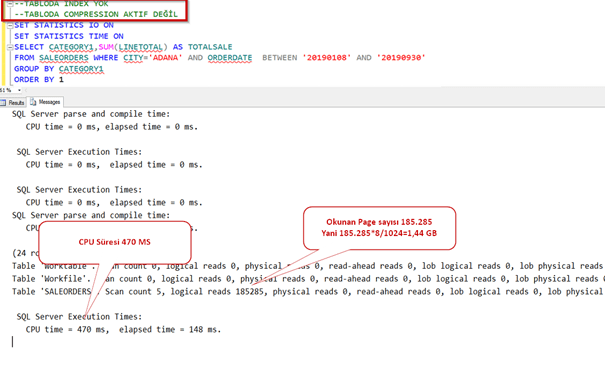
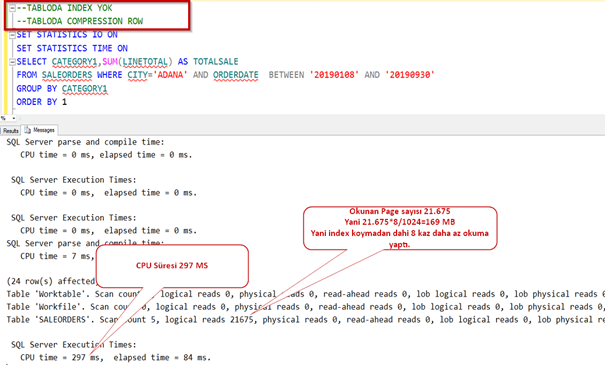
Tablomuzdan 2019 Ağustos ayında Adana şehrinde yapılan satışları indexli,indexsiz olarak çekeceğiz. Bakalım compression aktif ve pasif olduğunda nasıl sonuç döndürecek.
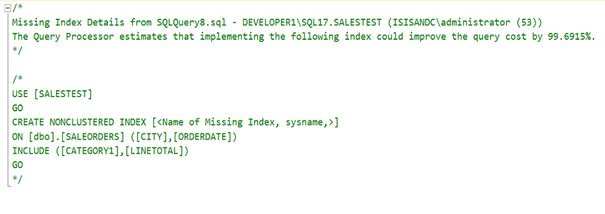
Şimdi SQL Server’ın bize önerdiği indexi ekleyelim.
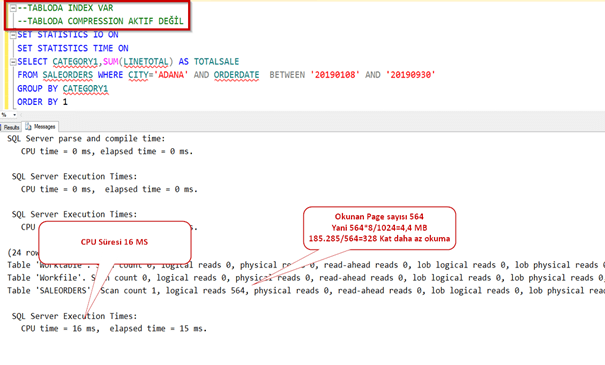
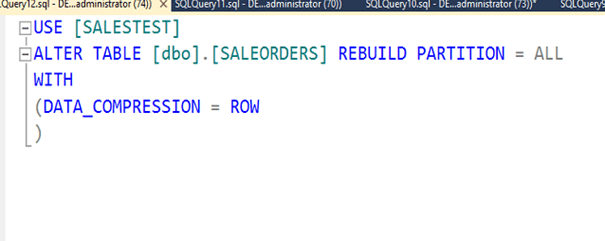
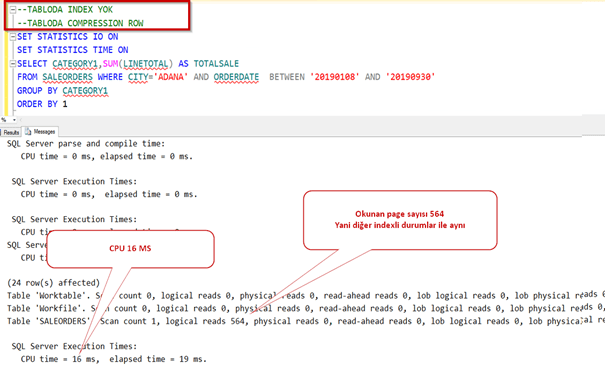
Şimdi row compression yapıp deneyelim.
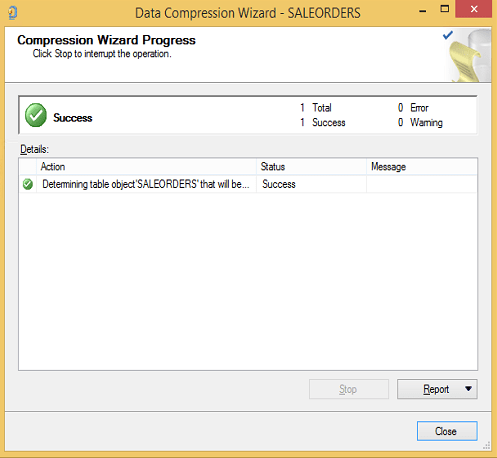
İşlem tamamlandı. Şimdi tablo boyutuna bakalım. Gördüğümüz gibi 160 MB civarına indi. Yani yaklaşık 8.5 kat sıkıştı.
Şimdi index’i silip sorgumuzu çalıştıralım.
Normalde sıkıştırma yaptığı zaman daha uzun sürede gelmesini bekleriz. Oysa daha az okuma yaptığı için sistem 8 kat daha performanslı çalıştı.
Şimdi index ekleyip tekrar çalıştıralım.
Gördüğümüz gibi indexin şu an için sıkıştırmada bir payı olmadığından sıkıştırma aktifken ya da pasifken bir fark olmadı.
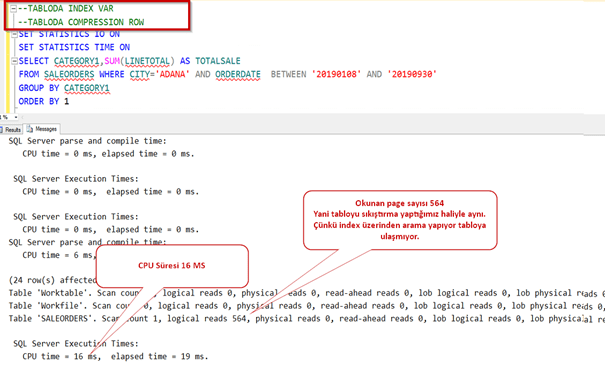
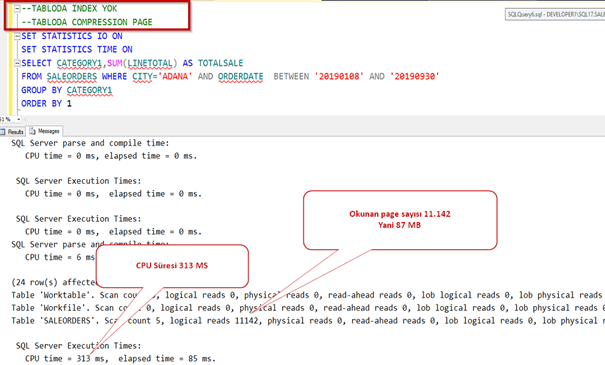
Şimdi de page bazlı compression’a bakalım.
Data boyutu tahmin edilenden daha aza indi. Yaklaşık 80 MB oldu.
Şimdi performansa bakalım.
Önce index i silelim.
Index yokken bile çok iyi sonuç getirdi. Hatırlayalım sıkıştırmadan önce 1,44 GB lık okuma yapıyordu burada ise sadece 87 MB.
Şimdi de indexi tekrar ekleyerek bakalım.
Özetle
Bu yazıda SQL Server’da compression özelliğini ve nasıl kullanılacağını anlattık.
2 GB lık bir database’i 85 MB’a kadar küçülttük.
Ayrıca row based ve page based sıkıştırmanın farkını gördük.
Son olarak compress aktif bir tabloda pasif olana göre beklediğimizin tam aksi daha az okuma ve daha fazla performans gösterdiğini gördük.
Bir database’in suspect moda düşmesi demek database dosyalarından (mdf,ldf,ndf) en az birini okurken bir sorunla karşılaşmış olması anlamına gelir.
Genel olarak bu sorunlar,
Database dosyaları bozulmuş olabilir.
Sistemde yeterli disk alanı kalmamış olabilir.
Yeterli memory kalmamış olabilir.
Database dosyaları silinmiş ya da işletim sistemi dosyaların kullanılmasına izin vermiyor olabilir.
Server düzgün kapatılmadığı için ya da bir takım donanımsal sorunlar yüzünden dosyalar okunamıyor olabilir.
Bu moda düşen bir database’i normale çevirmek için aşağıdaki komutları kullanırız.
–Database’in statüsünü resetleme komutu. Böylece manuel müdaheleye izin verir. EXEC sp_resetstatus ‘dbName’; –Database’i emergency moda çekiyoruz. ALTER DATABASE dbName SET EMERGENCY ;
–Log dosyası silinir ve yeni bir yeni boş bir log dosyası oluşturulur. Bu sırada log dosyasındaki –kaydedilmeyen veriler silinir. DBCC CheckDB (‘dbName’, REPAIR_ALLOW_DATA_LOSS) –Database’i kullanıma açıyoruz. ALTER DATABASE dbName SET MULTI_USER Database’imizi artık gönül rahatlığıyla selectleyebiliriz:)