

Hi,
In this article, i will talk about, choosing right data types and normalization on database tables.
The “Database” is a basic word. It contains “Data” and “Base” words. So it means “The Base of Data”.
So, in databases, the correct definition of the data is more important than we guess.
We define the variable as “string” while we are coding.
But in database systems, there are a lot of data types to define a string data.
Unfortunately, we generally use nchar for string values and use bigint for integer values.
In this article, I will explain, how this situation causes a big problem.
Now, let’s imagine!
We have a task. Our task is to design a citizenship database table for a country.
For example my country Turkey. The population is now about 85 million. Let’s assume that with the people who died and the family tree, we have about 200 million people in our database.
Let’s design the table.
First of all, we have an ID column. The column has an auto-increment value and it is also the primary key of the table.
And the other columns are here.
ID :Auto increment primary key value
CITIZENNUMBER :11 digits unique citizen number
CITYID :The id number of the city where the citizen was born
TOWNID :The id number of the town where the citizen currently lives
DISTRICTID :The id number of the district where the citizen currently lives
NAMESURNAME :The citizen’s name surname info
I think these are enough for an easy understanding of the subject.
Actually, this is enough to understand the results of wrong datatypes.
Let’s start from the ID column. We think firstly, this column will address about 200 million rows. So this is a very big value. So we think that we must use the “bigint” data type.
The next column is CITIZENNUMBER. This has 11 digits number and we choose the bigint again.
And the other columns are also integer values. Then let’s choose the bigint for all of them too.


We have just one table and just 5 numeric columns. I think it is too much.
Well, how can we reduce this huge space? Of course, by using the correct data types.
The bigint data types addresses values between -2^63 and +2^63.
Ok, do we need this huge gap for 200 million rows?
Of course not.
We have also an integer data type. The integer data type addresses values between -2^32 ile +2^32. It means between about -2 Billion and +2 Billion.
So, for the ID column, the integer data type is enough and better than the bigint. Because the integer data type uses just 4 Bytes. It is two times better than the bigint. And we know that the population will never be more than 2 Billion.
CITIZENNUMBER: This column has 11 digits number. So an 11 digits value needs bigint.
CITYID: This column identifies the city Id from the Cities table. In Turkey country, we have just 81 cities and we know that it will always be less than 255. So we can use the TinyInt data types for the CityID column. The Tinyint datatype addresses the values between 1 and 255 and it uses just 1 Byte for a value.
TOWNIND: In Turkey, there are about 1.000 towns. So we can’t use the tinyint because it is not enough. But, we don’t want to use the integer. Because 2 Billion is so much for a value between 1 and 1000. There is another data type Smallint. The Smallint data type addresses the values between -32.000 and +32.000. So the Smallint is suitable for the TOWNID column.
DISTRICTID:
Turkey has about 55.000 districts. So I can’t use the Tinyint and Smallint. But the Bigint is so much for this type of value. Then the Integer is good for this column.
Now, let’s calculate again. We can see the total space. It is about 3.54 GB. It is about two times better than the first design.

In the country, there are citizens from all over the World. So if we define a max character limit, we have to calculate the max character limit of the names from all over the World.
For example, I know that the Spanish people have the longest names. Because they give names to their children as father’s, grand father’s, grand grand father’s names. 😊
For example
“pablo diego josé francisco de paula juan nepomuceno maría de los remedios cipriano de la santísima trinidad ruiz y Picasso”
We just say “Pablo Picasso” 😊
If we want to keep this name-surname information on the database, we have to use 250 digits for namesurname.
This data type is a string. But in database systems, there are so many data types used for string values.
Char, nchar, varchar,nvarchar etc.
Let’s explain the differences between these types with a basic example.
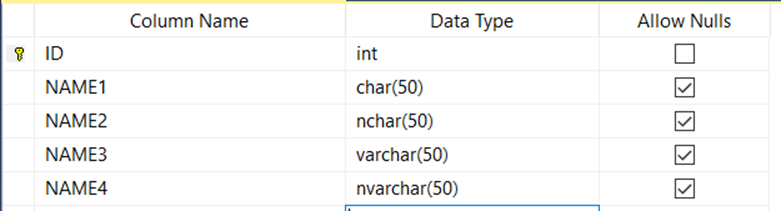
Let’s create a table with the columns below and save it as TEST.
ID:Int
NAME1:char(50)
NAME2:nchar(50)
NAME3:varchar(50)
NAME4:nvarchar(50)
Let’s insert my name, “ÖMER” to the table.



I copy the value from the NAME1 column and paste it into an empty place.



It is blinking far from the end of the string value. The name value “ÖMER” has 4 digits length but the cursor is blinking at 50 digits length. It means, the char(50) uses 50 digits for any value less or equal to 50 digits. It is a very big disadvantage. Think! We have a lot of short names, for example, Jhon, Marry, May, etc. Their average length is just 4 characters and it is a really huge waste.
Let’s investigate the NAME2 column. Copy the NAME2 column and paste it into the text area.


The situation is the same. The cursor is blinking at the end of the 50th character. So, we can say that char and nchar may be the same.
Now let’s look at NAME3 and NAME4 columns. NAME3 is varchar and NAME4 is Nvarchar. Copy the NAME3 and paste into the free text space.
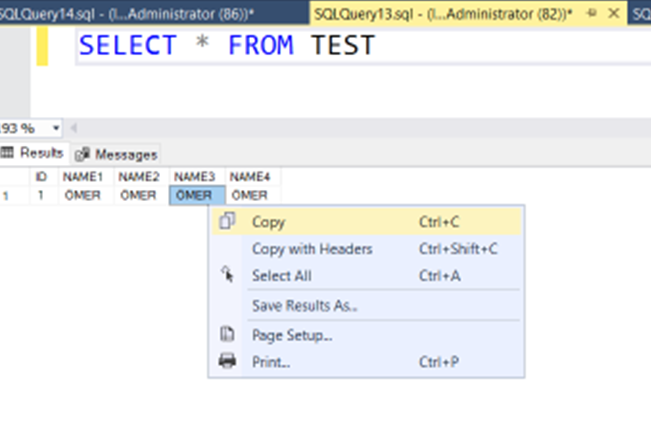

Can you see where the cursor is blinking? The cursor is blinking at the end of the string. The length of the string is 4 digits and the cursor is blinking here. So we can understand that the varchar data type uses space as the string value’s length not max length.
According to this scenario, the char data type uses 50 digits and varchar uses just 4 digits. I think it’s really better than the char or nchar.
We can see that the Nvarchar is the same as the varchar. We don’t know what the “N” means on Nchar or Nvarchar does yet.
The “N” character symbolizes Unicode support. Unicode means the international characters.
Let me show you with an example to understand what Unicode support is.
I use google translate and translate a word to into Chinese. The first word that comes to my mind is book. In Chinese, “书” word means “book”. So I copy this word and paste it into the table.

And I select the data from the table below.

You can see that in the NAME1 and NAME3 columns we can’t see the Chinese character. These columns are both char and varchar and do not support the Unicode characters. It is very easy to understand. Char and Varchar data types use 1 Byte for each letter or character. 1 Byte means 0-255 different numbers. For example, in alphabet, there are 26 characters. So we have 26 lowercase and 26 uppercase letters, 10 numbers, and a lot of punctuations. 255 is enough to address all these letters. But think about the Japanese alphabet. The Japanese alphabet has about 2.000 letters. So 1 byte is not enough for all these characters. We need more. Maybe 2 Bytes can be suitable for us. 2 bytes addresses about 32.000 different letters. Nchar and Nvarchar uses 2 bytes for a letter and can show the Unicode characters.
Let’s turn the scenario again. We have 200 million rows that include namesurname column with max 250 digits and with Unicode support.
Then we have to use nchar(250) or nvarchar(250).
Using nchar(250) is a wrong stuation. Because 250 is just a limit but we arrange 250×2=500 Bytes for all namesurnames.
Using nvarchar (250) is the best choice. Because it supports Unicode characters and also uses space as the namesurname’s length.
Let’s calculate again
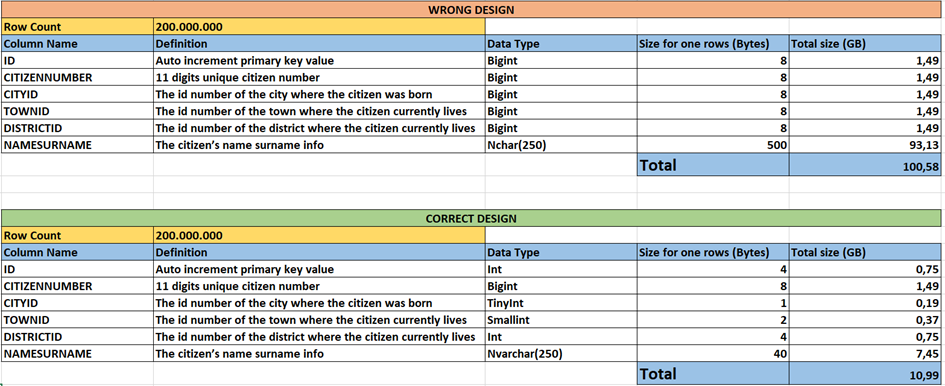
As you see, in the wrong design, we use about 100 GB. But in the correct design, we use just 11 GB. It is 10 times smaller than the first one.
We are talking about just one table and just 6 columns. And even in this situation, we can see a huge difference.
In database systems, we have a lot of tables with a lot of columns.
In this article, we talked about the normalization and importance of choosing the right data type.
We talked about the size of the data. You can think that it is only about the size on the disk and you can ignore all these calculations in your mind. You can say “It is all about the money. I can use bigger storage.” But it is a wrong approach. Because it is not about just the storage. Because SQL Server works on memory and uses the CPU.
If the data type is bigint, You use 8 Byte space on your ram for the for example, 15 number.
If the data type is tinyint, You use 1 Byte space on your ram for the 15 number.
And also if you use bigint, you can use your CPU 8 times more.
As a result,
The Normalization and the knowing to use the right data types are more important than we guess.
See you again in the next article.

Hey Omer, great read! I particularly enjoyed your in-depth discussion of the byte storage of the varchar data type, since it was something I hadn’t really thought of before. Being a fellow blogger myself, I also really appreciate how organized and well-formatted everything was – it definitely made the content much more digestible overall. Keep up the awesome work!
BeğenLiked by 1 kişi
Thank you so much Rohak for this great comment. Be sure friend, I will keep up. 🙂
BeğenBeğen